Introdução
Ideia Geral
Utilizando os dados de câncer da FOSP, somente do tipo colorretal, serão utilizados quatro modelos de machine learning diferentes, com o intuito de testar diferentes tipos de algoritmo na classificação de sobrevida por três anos.
O label é 0 se o paciente não sobreviveu após três anos do diagnóstico e 1 se sobreviveu.
Modelos de ML
Foram escolhidos os modelos Naive Bayes, que utiliza o Teorema de Bayes para realizar as previsões, Random Forest, XGBoost e LightGBM, que utilizam os conceitos de árvores de decisão, além de bagging e boosting. Além disso, será testado um modelo de votação com os melhores classificadores obtidos, visando obter um algoritmo ainda mais acertivo.
Validação dos modelos
Para validar os modelos treinados foi utilizada primeiramente a matriz de confusão, sendo possível avaliar os acertos em ambas as classes. Para entender de houve overfitting nos modelos, foi utilizada a curva ROC para os conjuntos de treino e teste, comparando a métrica AUC entre ambos os conjuntos.
Por fim, os modelos Random Forest, XGBoost e LightGBM oferecem a possibilidade de saber quais foram as features mais importantes, ou seja, que mais influenciam na previsão das classes. Assim, foram mostradas duas maneiras diferentes de analisar a importância das variáveis de entrada, uma usando a própria função dos modelos e outra usando a biblioteca SHAP, que mostra a influência das features em ambas as classes.
[ ]:
# Leitura dos dados
df = read_csv('/content/drive/MyDrive/Trabalho/Cancer/Datasets/colorretal_labels.csv')
df.head(3)
(31916, 37)
| ESCOLARI | IDADE | SEXO | IBGE | CATEATEND | DIAGPREV | EC | ECGRUP | TRATHOSP | NENHUM | ... | IBGEATEN | ULTICONS | ULTIDIAG | ULTITRAT | obito_geral | obito_cancer | vivo_ano1 | vivo_ano3 | vivo_ano5 | ESCOLARI_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 19 | 2 | 3538709 | 9 | 2 | IV | IV | I | 0 | ... | 3538709 | 4985 | 4985 | 4951 | 0 | 0 | 1 | 1 | 1 | 4.0 |
| 1 | 9 | 19 | 1 | 3537107 | 2 | 2 | IIIA | III | I | 0 | ... | 3509502 | 2680 | 2744 | 2674 | 1 | 1 | 1 | 1 | 1 | 4.0 |
| 2 | 4 | 19 | 1 | 3516200 | 9 | 2 | IIB | II | F | 0 | ... | 3516200 | 4725 | 4734 | 4719 | 0 | 0 | 1 | 1 | 1 | 4.0 |
3 rows × 37 columns
[ ]:
# Valores faltantes
df.isna().sum().sort_values(ascending=False).head(6)
ESCOLARI 0
CONSDIAG 0
DIAGTRAT 0
ANODIAG 0
FAIXAETAR 0
DRS 0
dtype: int64
[ ]:
# Correlação com a saída
corr_matrix = df.corr()
abs(corr_matrix['vivo_ano3']).sort_values(ascending = False).head(20)
The default value of numeric_only in DataFrame.corr is deprecated. In a future version, it will default to False. Select only valid columns or specify the value of numeric_only to silence this warning.
vivo_ano3 1.000000
ULTIDIAG 0.757341
ULTICONS 0.753018
ULTITRAT 0.751754
vivo_ano5 0.698727
vivo_ano1 0.529451
obito_cancer 0.384454
obito_geral 0.370056
ANODIAG 0.230827
CIRURGIA 0.214017
ULTINFO 0.170955
OUTROS 0.079260
IDADE 0.071979
CATEATEND 0.062563
DIAGTRAT 0.048280
RADIO 0.044041
RECNENHUM 0.041957
TRATCONS 0.038209
HORMONIO 0.036303
SEXO 0.034967
Name: vivo_ano3, dtype: float64
[ ]:
# Quantidade de pacientes em cada classe da saída
df.vivo_ano3.value_counts()
0 18278
1 13638
Name: vivo_ano3, dtype: int64
DataFrame vivo_ano3
Antes de realizar o pré-processamento dos dados é necessário filtrar os dados, de modo a retirar pacientes que não foram acompanhados por pelo menos três anos e que a última informação consta como vivos.
[ ]:
# Dataset da sobrevida de três anos
df_ano3 = df[~((df.obito_geral == 0) & (df.vivo_ano3 == 0))].reset_index(drop=True)
df_ano3.shape
(26231, 37)
[ ]:
df_ano3.head(3)
| ESCOLARI | IDADE | SEXO | IBGE | CATEATEND | DIAGPREV | EC | ECGRUP | TRATHOSP | NENHUM | ... | IBGEATEN | ULTICONS | ULTIDIAG | ULTITRAT | obito_geral | obito_cancer | vivo_ano1 | vivo_ano3 | vivo_ano5 | ESCOLARI_2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 19 | 2 | 3538709 | 9 | 2 | IV | IV | I | 0 | ... | 3538709 | 4985 | 4985 | 4951 | 0 | 0 | 1 | 1 | 1 | 4.0 |
| 1 | 9 | 19 | 1 | 3537107 | 2 | 2 | IIIA | III | I | 0 | ... | 3509502 | 2680 | 2744 | 2674 | 1 | 1 | 1 | 1 | 1 | 4.0 |
| 2 | 4 | 19 | 1 | 3516200 | 9 | 2 | IIB | II | F | 0 | ... | 3516200 | 4725 | 4734 | 4719 | 0 | 0 | 1 | 1 | 1 | 4.0 |
3 rows × 37 columns
Análise - Sobrevida três anos
Pré-processamento
Como o dataset já foi limpo anteriormente, aqui na etapa de pré-processamento serão realizadas a divisão dos dados em treino e teste, a codificação das colunas textuais para colunas numéricas e a normalização dos dados. Com isso, temos os dados prontos para o treinamento dos modelos de machine learning e consequentemente sua validação.
Neste primeiro momento, serão definidas as colunas que não serão utilizadas como features, assim, foi escolhido manter a coluna IDADE, então a coluna FAIXAETAR será retirada. O mesmo ocorre com a coluna EC, retirando a coluna ECGRUP. Por fim, as outras colunas contidas na list_drop são possíveis saídas para os modelos, mas estamos interessados somente na sobrevida de três anos, por isso só ela será mantida como label e as outras serão retiradas.
[ ]:
list_drop = ['FAIXAETAR', 'ULTICONS', 'ULTIDIAG', 'ULTITRAT', 'obito_geral',
'vivo_ano1', 'vivo_ano5', 'ULTINFO', 'obito_cancer', 'ECGRUP', 'ESCOLARI']
lb = 'vivo_ano3'
Uma função foi criada para realizar o pré-processamento inteiro, chamada preprocessing, internamente ela utiliza outras funções criadas que são: get_train_test (divide os dados em treino e teste), train_preprocessing (prepara os dados de treino) e test_preprocessing (prepara os dados de teste).
Mais detalhes em funções.
[ ]:
X_train, X_test, y_train, y_test, feat_cols, enc, norm = preprocessing(df_ano3, list_drop, lb,
random_state=seed,
balance_data=False,
encoder_type='LabelEncoder',
norm_name='StandardScaler',
return_enc_norm=True)
X_train = (19673, 25), X_test = (6558, 25)
y_train = (19673,), y_test = (6558,)
[ ]:
y_train.value_counts(normalize=True)
1 0.5199
0 0.4801
Name: vivo_ano3, dtype: float64
[ ]:
y_test.value_counts(normalize=True)
1 0.519976
0 0.480024
Name: vivo_ano3, dtype: float64
Treinamento e validação dos modelos de machine learning
Depois das etapas de preparação, os dados estão prontos para serem utilizados nos modelos escolhidos.
Naive Bayes
[ ]:
# Criação e treinamento do modelo Naive Bayes
nb = GaussianNB()
nb.fit(X_train, y_train)
GaussianNB()In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
GaussianNB()
[ ]:
# Matriz de confusão
plot_confusion_matrix(nb, X_test, y_test)
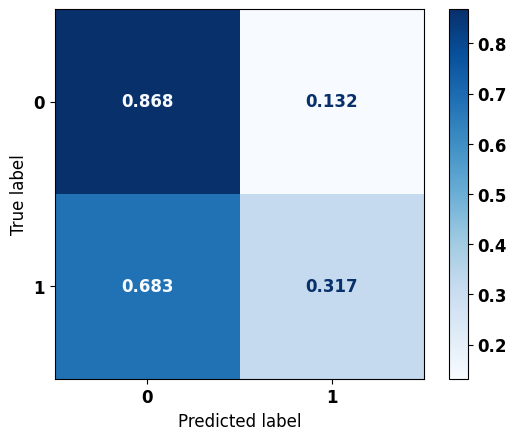
precision recall f1-score support
0 0.540 0.868 0.666 3148
1 0.723 0.317 0.441 3410
accuracy 0.582 6558
macro avg 0.631 0.593 0.553 6558
weighted avg 0.635 0.582 0.549 6558
Claramente percebe-se que o modelo previu boa parte dos dados como sendo da classe 0, portanto não teve um aprendizado satisfatório.
Na matriz de confusão, buscamos uma diagonal principal equilibrada e com a maior acertividade possível.
[ ]:
# Curva ROC
plot_roc_curve(nb, X_train, X_test, y_train, y_test)
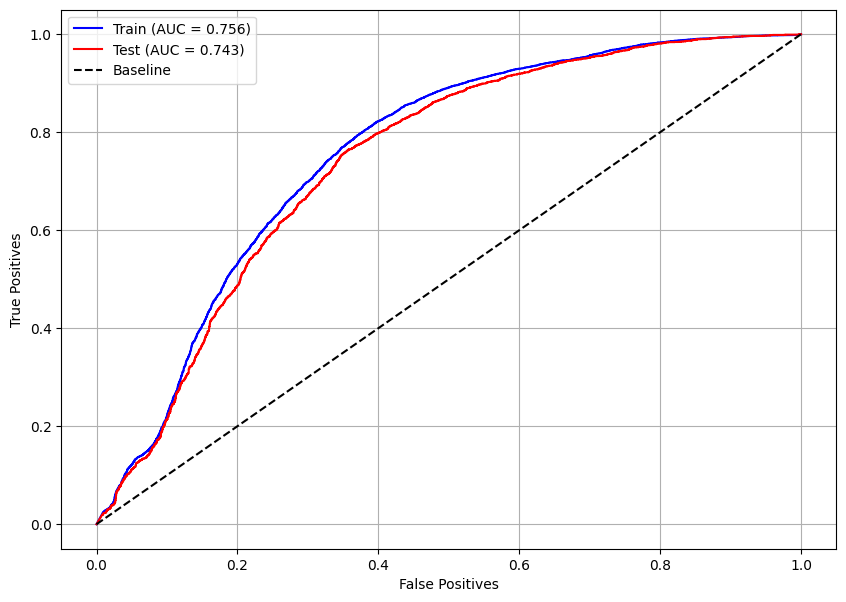
Pelas curvas ROC, pode-se dizer que não há overfitting, mas o modelo é ruim para a previsão da classe 1, portanto qualquer análise além dessa não possui tanta relevância.
Random Forest
O modelo Random Forest é mais complexo em relação ao Naive Bayes, assim alguns hiperparâmetros serão definidos para obter um modelo base e depois será realizada a busca dos melhores parâmetros utilizando o Optuna.
Os parâmetros definidos para este primeiro modelo serão:
random_state: para repetibilidade do treinamento do modelo. Será utilizado na busca pelos hiperparâmetros também, sempre como mesmo valor definido na variávelseed.max_depth: será definido como 8, pois o padrão do modelo é não ter profundidade máxima para as árvores, o que dificulta e faz o treinamento ser muito longo, além da maior chance de overfitting.class_weight: usado para definir os pesos de cada classe no treinamento do modelo, muito útil quando temos classes desbalanceadas no conjunto de dados, como neste caso.
[ ]:
# Criação e treinamento do modelo Random Forest
rf = RandomForestClassifier(random_state=seed,
class_weight={0:1.44, 1:1},
max_depth=8,
criterion='entropy')
rf.fit(X_train, y_train)
RandomForestClassifier(class_weight={0: 1.44, 1: 1}, criterion='entropy',
max_depth=8, random_state=10)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(class_weight={0: 1.44, 1: 1}, criterion='entropy',
max_depth=8, random_state=10)[ ]:
# Matriz de confusão
plot_confusion_matrix(rf, X_test, y_test)
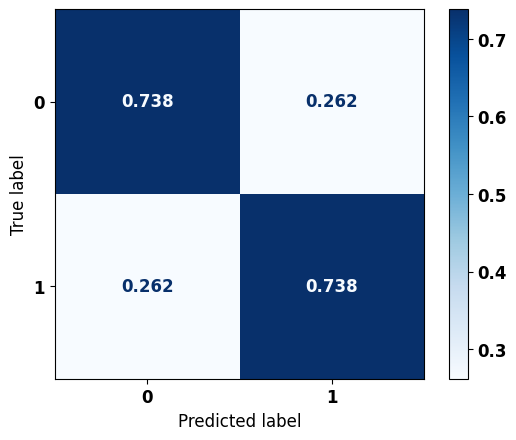
precision recall f1-score support
0 0.722 0.738 0.730 3148
1 0.753 0.738 0.746 3410
accuracy 0.738 6558
macro avg 0.738 0.738 0.738 6558
weighted avg 0.738 0.738 0.738 6558
A matriz obtida para o modelo Random Forest apresentou diagonal equilibrada em ambas as classes, com 74% de acurácia.
[ ]:
show_tree(rf, feat_cols, 2)
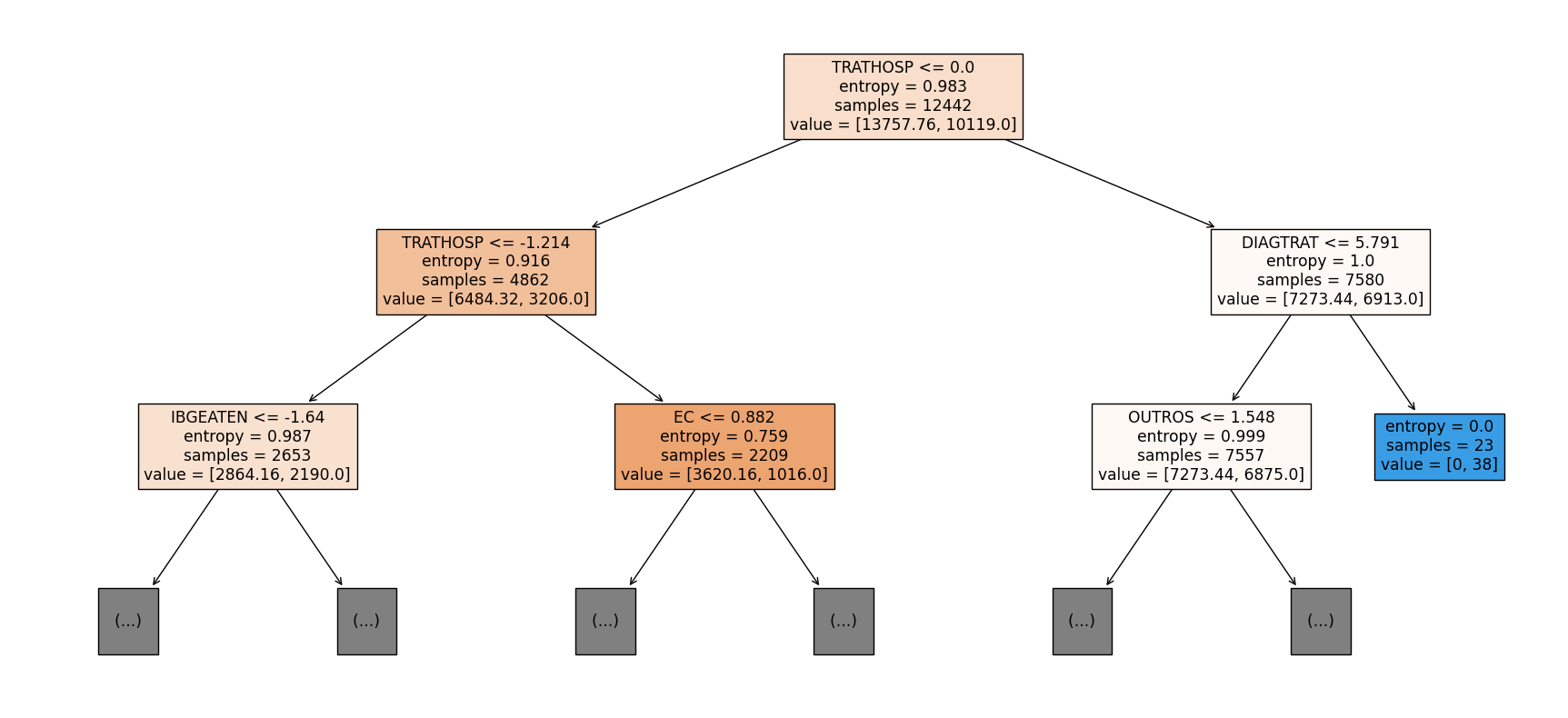
[ ]:
# Curva ROC
plot_roc_curve(rf, X_train, X_test, y_train, y_test)
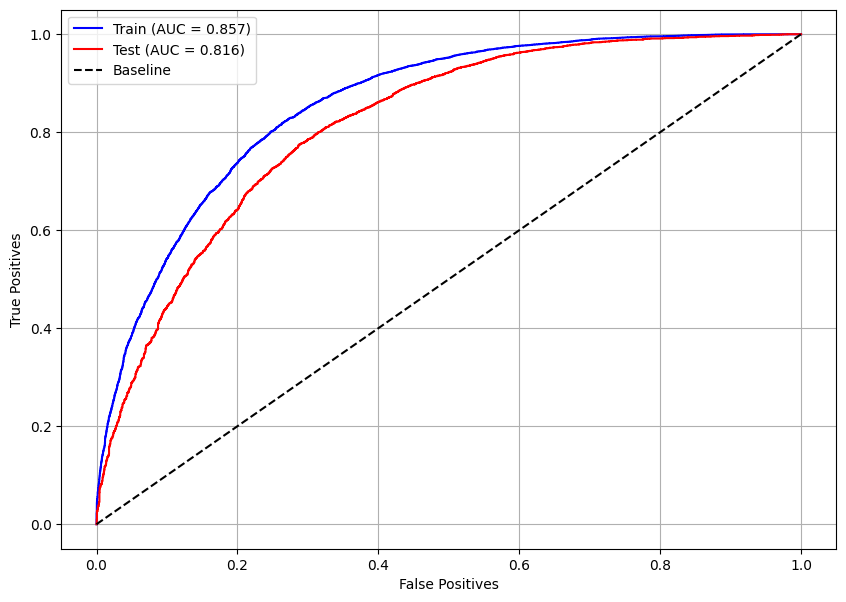
Como a métrica AUC possui valores próximos para o conjunto de treino e de teste, 0,857 e 0,816 respectivamente, pode-se dizer que há apenas um pouco de overfitting, não sendo algo de grande preocupação.
[ ]:
# Importância das features
plot_feat_importances(rf, feat_cols)
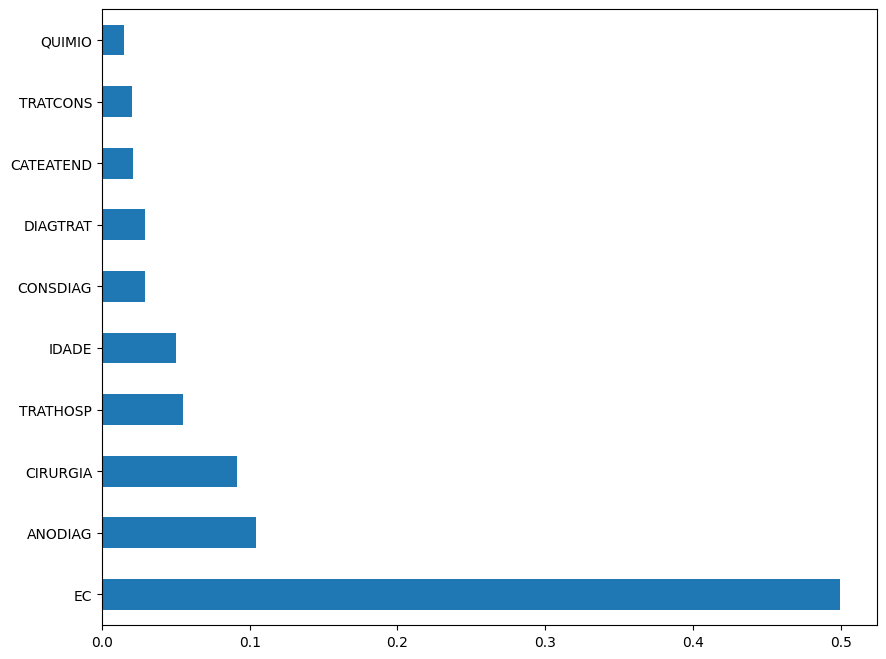
As features mais importantes nesta visualização são
EC, com uma grande vantagem,ANODIAG,CIRURGIAeTRATHOSP.
[ ]:
# Importância das features pelos valores SHAP
plot_shap_values(rf, X_train, feat_cols)
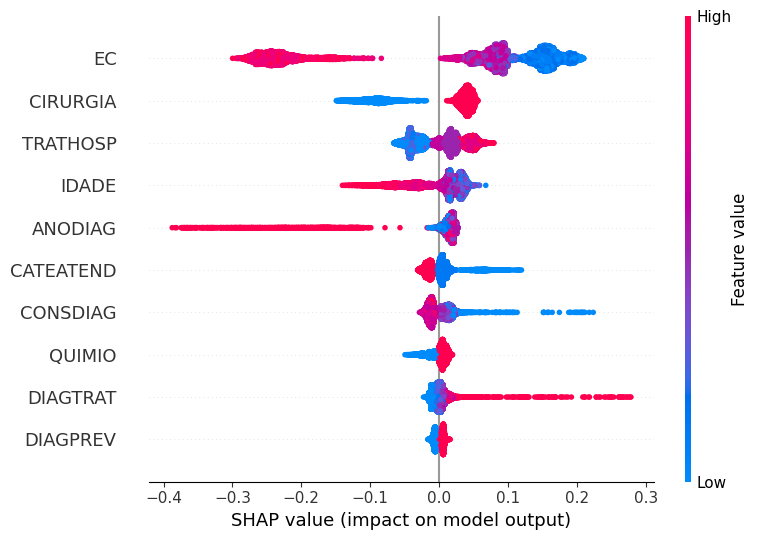
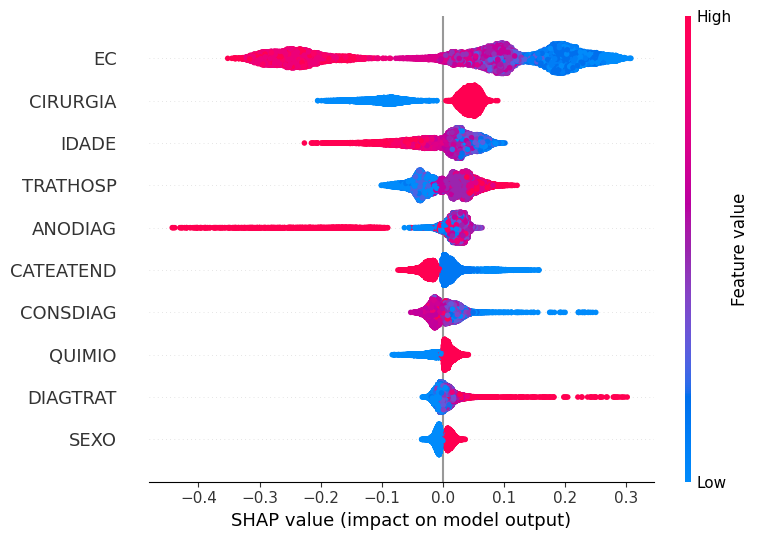
A coluna EC foi a mais importante aqui também, com isso, os valores mais altos desta variável, mostrados em rosa, influenciaram mais o modelo na previsão da classe 0 (não sobreviveu ao terceiro ano após o diagnóstico). Já os valores mais baixos desta coluna, em azul, tem mais peso para previsão ser da classe 1. Este comportamento faz sentido, pois quanto mais alto o estágio, maior é a extensão do câncer, assim menor a chance de sobrevivência.
O raciocínio para analisar as outras colunas é o mesmo utilizado para o estadiamento clínico.
Optuna
Para fazer a busca pelos melhores hiperparâmetros, será utilizado a biblioteca Optuna, definindo o intervalo para os parâmetros do modelo a serem buscados.
[ ]:
# Folds com a mesma proporção das classes
skf = StratifiedKFold(10, shuffle=True, random_state=seed)
[ ]:
# Função com o modelos e seus parâmetros, que terá sua métrica maximizada
def objective(trial):
n_estimators = trial.suggest_int('n_estimators', 50, 250)
max_depth = trial.suggest_int('max_depth', 3, 18)
min_samples_split = trial.suggest_int('min_samples_split', 2, 10)
min_samples_leaf = trial.suggest_int('min_samples_leaf', 1, 7)
max_samples = trial.suggest_float('max_samples', 0.7, 1.0, step=0.1)
optimizer = trial.suggest_categorical('criterion', ['gini', 'entropy'])
cls = RandomForestClassifier(n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
min_samples_leaf=min_samples_leaf,
max_samples=max_samples,
criterion=optimizer,
random_state=seed)
return cross_val_score(cls, X_train, y_train,
cv=skf, scoring='balanced_accuracy').mean()
[ ]:
# Criação do estudo e procura pelos hiperparâmetros
studyRF = optuna.create_study(direction='maximize', sampler=RandomSampler(seed))
studyRF.optimize(objective, n_trials=100)
[ ]:
# Melhor tentativa
studyRF.best_trial
FrozenTrial(number=19, state=TrialState.COMPLETE, values=[0.7653298572918547], datetime_start=datetime.datetime(2023, 4, 11, 20, 11, 17, 514783), datetime_complete=datetime.datetime(2023, 4, 11, 20, 11, 54, 979541), params={'n_estimators': 126, 'max_depth': 17, 'min_samples_split': 10, 'min_samples_leaf': 4, 'max_samples': 0.8999999999999999, 'criterion': 'entropy'}, user_attrs={}, system_attrs={}, intermediate_values={}, distributions={'n_estimators': IntDistribution(high=250, log=False, low=50, step=1), 'max_depth': IntDistribution(high=18, log=False, low=3, step=1), 'min_samples_split': IntDistribution(high=10, log=False, low=2, step=1), 'min_samples_leaf': IntDistribution(high=7, log=False, low=1, step=1), 'max_samples': FloatDistribution(high=1.0, log=False, low=0.7, step=0.1), 'criterion': CategoricalDistribution(choices=('gini', 'entropy'))}, trial_id=19, value=None)
[ ]:
# Melhores parâmetros
studyRF.best_params
{'n_estimators': 126,
'max_depth': 17,
'min_samples_split': 10,
'min_samples_leaf': 4,
'max_samples': 0.8999999999999999,
'criterion': 'entropy'}
[ ]:
plot_optimization_history(studyRF).show()
[ ]:
# Modelo com os melhores parâmetros
params = studyRF.best_params
params['random_state'] = seed
params['class_weight'] = {0: 1.725, 1: 1}
rf_optuna = RandomForestClassifier()
rf_optuna.set_params(**params)
rf_optuna.fit(X_train, y_train)
RandomForestClassifier(class_weight={0: 1.725, 1: 1}, criterion='entropy',
max_depth=17, max_samples=0.8999999999999999,
min_samples_leaf=4, min_samples_split=10,
n_estimators=126, random_state=10)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
RandomForestClassifier(class_weight={0: 1.725, 1: 1}, criterion='entropy',
max_depth=17, max_samples=0.8999999999999999,
min_samples_leaf=4, min_samples_split=10,
n_estimators=126, random_state=10)[ ]:
# Matriz de confusão do modelo Random Forest otimizado
plot_confusion_matrix(rf_optuna, X_test, y_test)
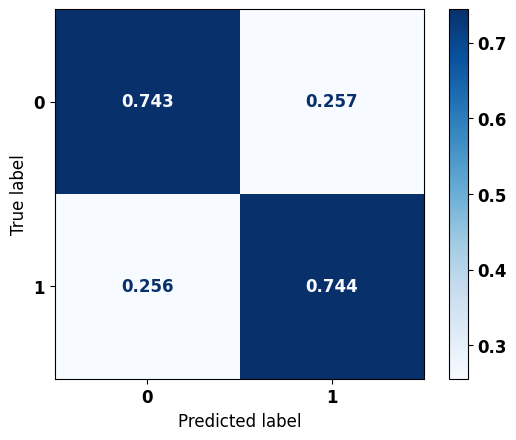
precision recall f1-score support
0 0.728 0.743 0.736 3148
1 0.758 0.744 0.751 3410
accuracy 0.744 6558
macro avg 0.743 0.744 0.743 6558
weighted avg 0.744 0.744 0.744 6558
Há uma melhora de acurácia em relação ao primeiro modelo testado, passando um pouco de 74%.
[ ]:
# Curva ROC do modelo otimizado
plot_roc_curve(rf_optuna, X_train, X_test, y_train, y_test)
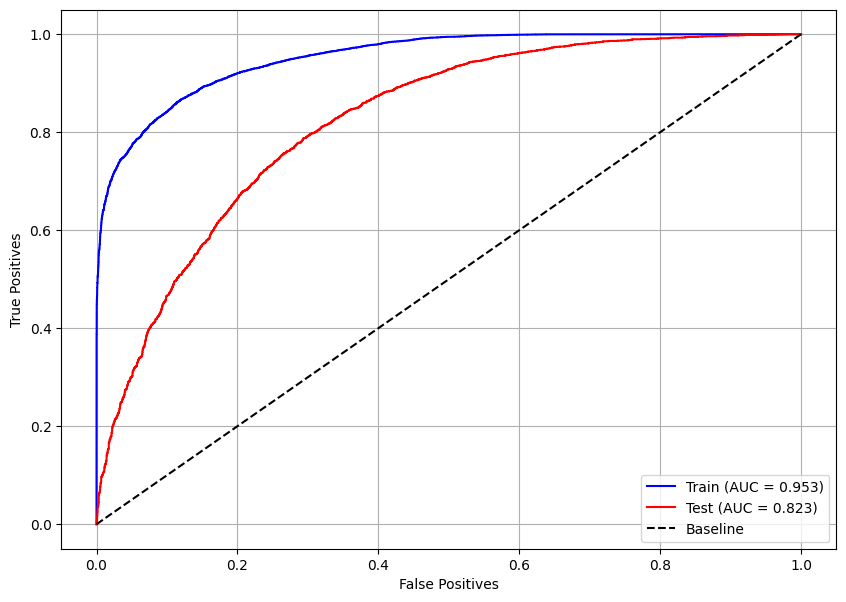
A curva ROC mostra que o modelo possui overfitting, pois para o conjunto de treino temos AUC = 0,953 e para o teste AUC = 0,823, essa diferença caracteriza o problema.
[ ]:
# Importância das features pelos valores SHAP
plot_shap_values(rf_optuna, X_train, feat_cols)
No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored
XGBoost
O modelo XGBoost também terá alguns hiperparâmetros definidos para obter um modelo base e depois será realizada a busca dos melhores parâmetros utilizando o Optuna.
Os parâmetros definidos para este primeiro modelo serão:
random_state: para repetibilidade do treinamento do modelo. Será utilizado na busca pelos hiperparâmetros também, sempre como mesmo valor definido na variávelseed.max_depth: será utilizado o valor 3, padrão do modelo.scale_pos_weight: usado para definir o peso da classe 1 no treinamento do modelo, pois temos classes desbalanceadas.
[ ]:
# Criação e treinamento do modelo XGBoost
xgb = XGBClassifier(max_depth=3,
scale_pos_weight=0.71,
random_state=seed)
xgb.fit(X_train, y_train)
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, gpu_id=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=3, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=10, ...)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=None, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=None, gpu_id=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=None, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=3, max_leaves=None,
min_child_weight=None, missing=nan, monotone_constraints=None,
n_estimators=100, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=10, ...)[ ]:
# Matriz de confusão
plot_confusion_matrix(xgb, X_test, y_test)
precision recall f1-score support
0 0.730 0.745 0.737 3148
1 0.760 0.746 0.753 3410
accuracy 0.746 6558
macro avg 0.745 0.745 0.745 6558
weighted avg 0.746 0.746 0.746 6558
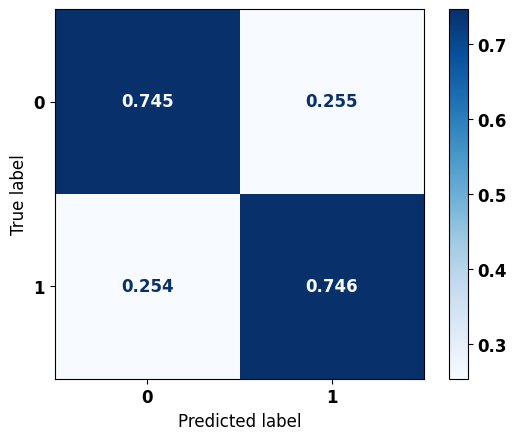
A matriz obtida para o modelo XGBoost apresentou diagonal equilibrada em ambas as classes, com 75% de acurácia.
[ ]:
# Curva ROC
plot_roc_curve(xgb, X_train, X_test, y_train, y_test)
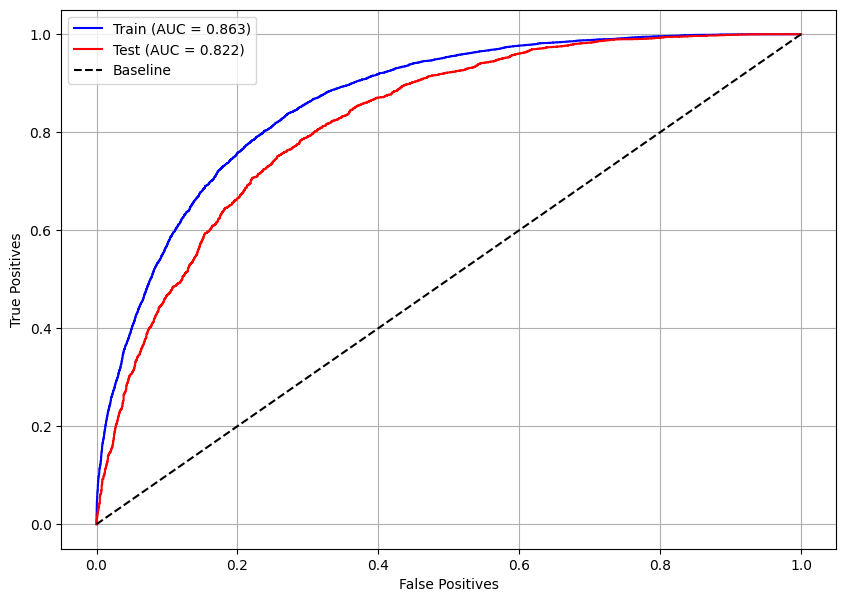
Como a métrica AUC possui valores próximos para o conjunto de treino e de teste, 0,863 e 0,822 respectivamente, pode-se dizer que há apenas um pouco de overfitting, não sendo algo de grande preocupação.
[ ]:
# Importância das features
plot_feat_importances(xgb, feat_cols)
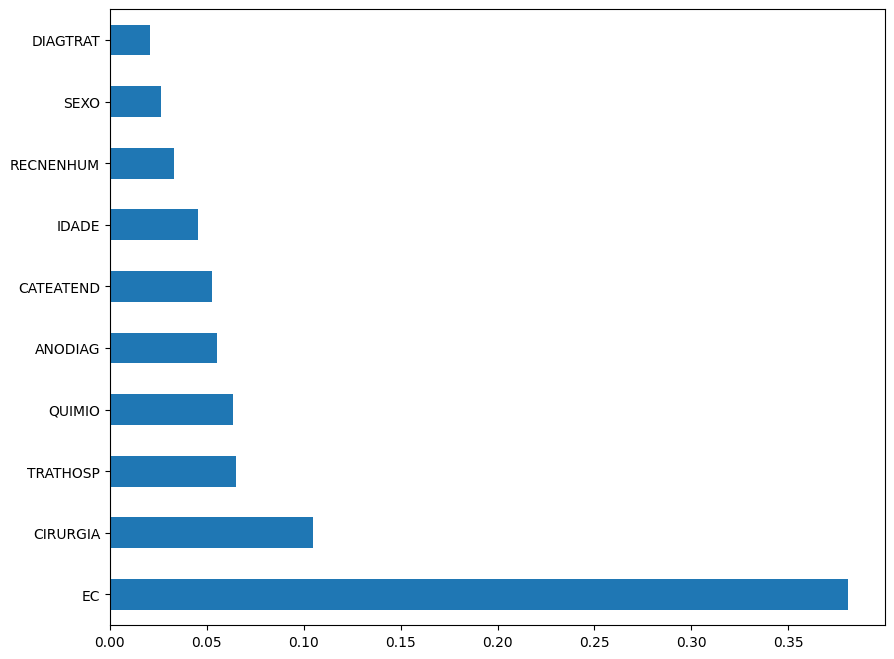
As features mais importantes nesta visualização são
EC, com boa vantagem,CIRURGIA,TRATHOSPeQUIMIO.
[ ]:
# Importância das features pelos valores SHAP
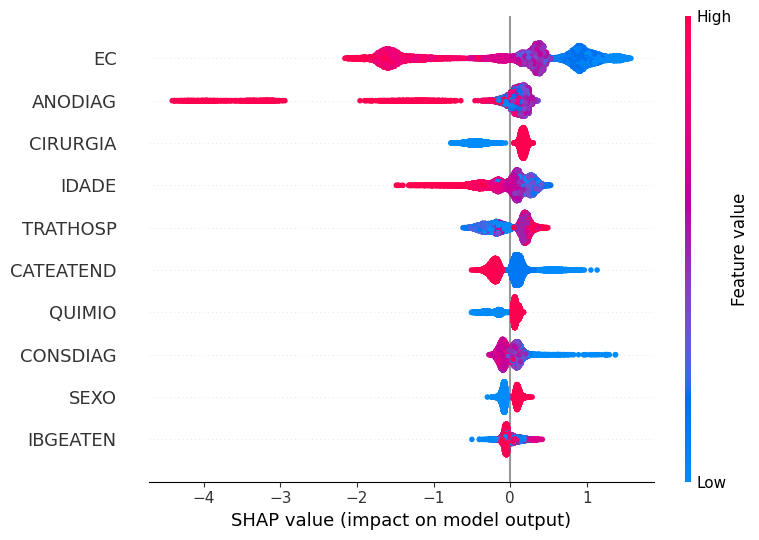
plot_shap_values(xgb, X_train, feat_cols)
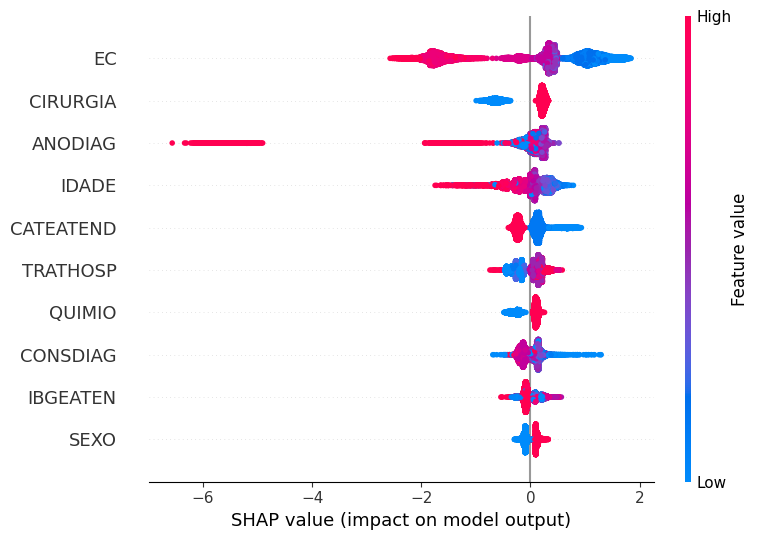
A coluna EC foi a mais importante aqui também, com isso, os valores mais altos desta variável, mostrados em rosa, influenciaram mais o modelo na previsão da classe 0 (não sobreviveu ao terceiro ano após o diagnóstico). Já os valores mais baixos desta coluna, em azul, tem mais peso para previsão ser da classe 1. Este comportamento faz sentido, pois quanto mais alto o estágio, maior é a extensão do câncer, assim menor a chance de sobrevivência.
O raciocínio para analisar as outras colunas é o mesmo utilizado para o estadiamento clínico.
Optuna
Para fazer a busca pelos melhores hiperparâmetros, será utilizado a biblioteca Optuna, definindo o intervalo para os parâmetros do modelo a serem buscados.
[ ]:
# Folds com a mesma proporção das classes
skf = StratifiedKFold(10, shuffle=True, random_state=seed)
[ ]:
# Função com o modelos e seus parâmetros, que terá sua métrica maximizada
def objective(trial):
n_estimators = trial.suggest_int('n_estimators', 50, 250)
max_depth = trial.suggest_int('max_depth', 3, 18)
learning_rate = trial.suggest_float('learning_rate', 0.05, 0.2, step=0.05)
gamma = trial.suggest_float('gamma', 0.0, 0.3, step=0.1)
min_child_weight = trial.suggest_int('min_child_weight', 1, 7)
colsample_bytree = trial.suggest_float('colsample_bytree', 0.3, 0.7, step=0.1)
cls = XGBClassifier(n_estimators=n_estimators,
max_depth=max_depth,
learning_rate=learning_rate,
gamma=gamma,
min_child_weight=min_child_weight,
colsample_bytree=colsample_bytree,
random_state=seed)
return cross_val_score(cls, X_train, y_train,
cv=skf, scoring='balanced_accuracy').mean()
[ ]:
# Criação do estudo e procura pelos hiperparâmetros
studyXGB = optuna.create_study(direction='maximize', sampler=RandomSampler(seed))
studyXGB.optimize(objective, n_trials=100)
[ ]:
# Melhor tentativa
studyXGB.best_trial
FrozenTrial(number=15, state=TrialState.COMPLETE, values=[0.7671206898090414], datetime_start=datetime.datetime(2023, 4, 11, 21, 5, 7, 264724), datetime_complete=datetime.datetime(2023, 4, 11, 21, 5, 41, 690207), params={'n_estimators': 145, 'max_depth': 7, 'learning_rate': 0.05, 'gamma': 0.3, 'min_child_weight': 3, 'colsample_bytree': 0.5}, user_attrs={}, system_attrs={}, intermediate_values={}, distributions={'n_estimators': IntDistribution(high=250, log=False, low=50, step=1), 'max_depth': IntDistribution(high=18, log=False, low=3, step=1), 'learning_rate': FloatDistribution(high=0.2, log=False, low=0.05, step=0.05), 'gamma': FloatDistribution(high=0.3, log=False, low=0.0, step=0.1), 'min_child_weight': IntDistribution(high=7, log=False, low=1, step=1), 'colsample_bytree': FloatDistribution(high=0.7, log=False, low=0.3, step=0.1)}, trial_id=15, value=None)
[ ]:
# Melhores parâmetros
studyXGB.best_params
{'n_estimators': 145,
'max_depth': 7,
'learning_rate': 0.05,
'gamma': 0.3,
'min_child_weight': 3,
'colsample_bytree': 0.5}
[ ]:
plot_optimization_history(studyXGB).show()
[ ]:
# Modelo com os melhores parâmetros
params = studyXGB.best_params
params['random_state'] = seed
params['scale_pos_weight'] = 0.69
xgb_optuna = XGBClassifier()
xgb_optuna.set_params(**params)
xgb_optuna.fit(X_train, y_train)
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=0.5, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=0.3, gpu_id=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=7, max_leaves=None,
min_child_weight=3, missing=nan, monotone_constraints=None,
n_estimators=145, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=10, ...)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
XGBClassifier(base_score=None, booster=None, callbacks=None,
colsample_bylevel=None, colsample_bynode=None,
colsample_bytree=0.5, early_stopping_rounds=None,
enable_categorical=False, eval_metric=None, feature_types=None,
gamma=0.3, gpu_id=None, grow_policy=None, importance_type=None,
interaction_constraints=None, learning_rate=0.05, max_bin=None,
max_cat_threshold=None, max_cat_to_onehot=None,
max_delta_step=None, max_depth=7, max_leaves=None,
min_child_weight=3, missing=nan, monotone_constraints=None,
n_estimators=145, n_jobs=None, num_parallel_tree=None,
predictor=None, random_state=10, ...)[ ]:
# Matriz de confusão do modelo XGBoost otimizado
plot_confusion_matrix(xgb_optuna, X_test, y_test)
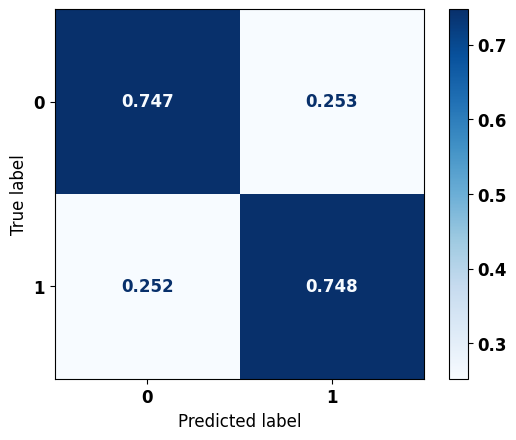
precision recall f1-score support
0 0.732 0.747 0.739 3148
1 0.762 0.748 0.755 3410
accuracy 0.747 6558
macro avg 0.747 0.747 0.747 6558
weighted avg 0.747 0.747 0.747 6558
Após a escolha dos hiperparâmetros, a acurácia de ambos os modelos ficou em torno de 75%.
[ ]:
# Curva ROC do modelo otimizado
plot_roc_curve(xgb_optuna, X_train, X_test, y_train, y_test)
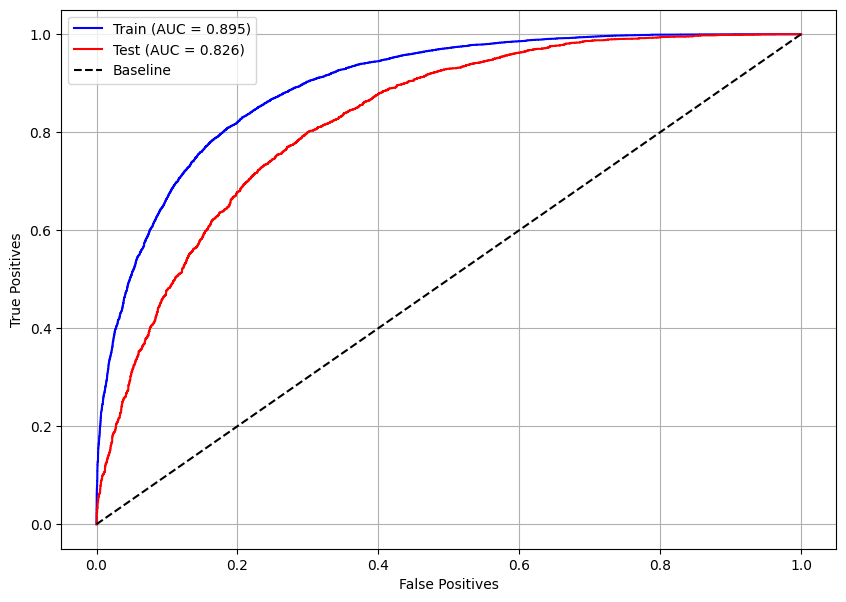
A curva ROC mostra que o modelo possui um pouco de overfitting, pois para o conjunto de treino temos AUC = 0,895 e para o teste AUC = 0,826, essa diferença caracteriza o problema.
[ ]:
# Importância das features pelos valores SHAP
plot_shap_values(xgb_optuna, X_train, feat_cols)
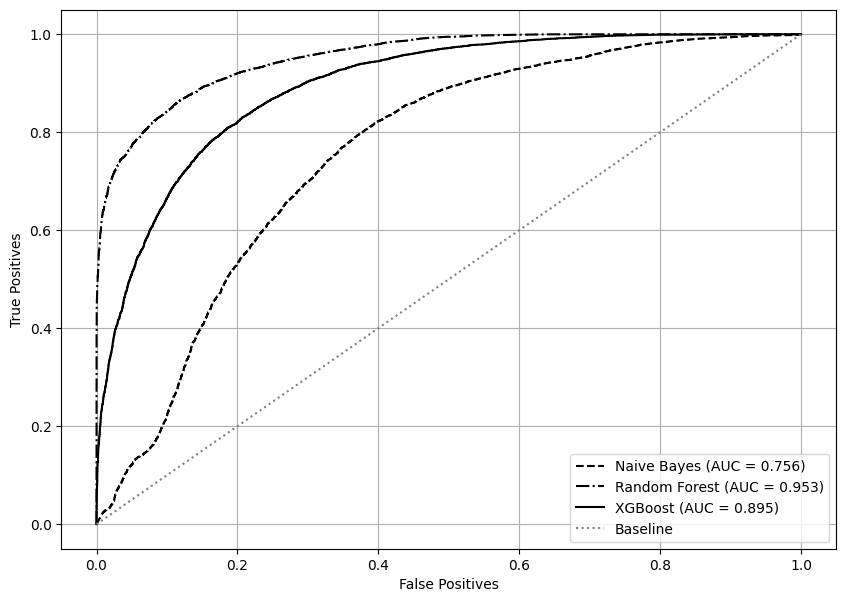
ROCs
[ ]:
# Treino
roc_together(X_train, y_train, nb, rf_optuna, xgb_optuna)
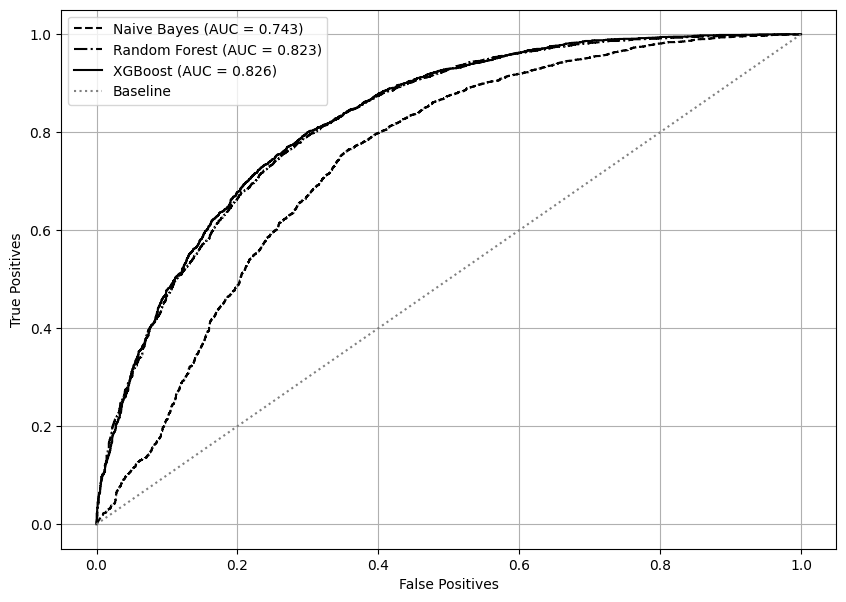
[ ]:
# Teste
roc_together(X_test, y_test, nb, rf_optuna, xgb_optuna)
RN
Importação das bibliotecas e funções
[ ]:
import tensorflow as tf
from tensorflow import keras
import matplotlib.pyplot as plt
[ ]:
from tensorflow.keras.models import Sequential, Model
from tensorflow.keras.layers import Dense, Dropout, Add, Input, Activation
from tensorflow.keras.optimizers import Adam
[ ]:
from tensorflow.keras.regularizers import l2
from tensorflow.keras.callbacks import EarlyStopping
[ ]:
# Definição de cores para gráficos
colors = plt.rcParams['axes.prop_cycle'].by_key()['color']
[ ]:
def plot_metrics(history):
"""Plot metrics after training the RNA.
:param history: RNA training history.
:return: no value
:rtype: none
"""
metrics = ['loss', 'accuracy', 'precision', 'recall']
plt.figure(figsize=(12,8))
for n, metric in enumerate(metrics):
name = metric.replace("_"," ").capitalize()
plt.subplot(2, 2, n + 1)
plt.plot(history.epoch, history.history[metric], color=colors[0], label='Train')
plt.plot(history.epoch, history.history['val_'+ metric],
color=colors[0], linestyle="--", label='Val')
plt.xlabel('Epoch')
plt.ylabel(name)
if metric == 'loss':
plt.ylim([0, plt.ylim()[1]])
if metric == 'accuracy':
plt.ylim([0.7, 1])
else:
plt.ylim([0, 1])
plt.legend()
Criação e treinamento da RNA Complexa
[ ]:
neg, pos = np.bincount(y_train)
total = neg + pos
print(f'Exemplos:\n Total: {total}\n Positivos: {pos} ({100*pos/total:.2f}% do total)')
# Cálculo dos pesos das duas classe
weight_for_0 = (1 / neg)*(total)/2.0
weight_for_1 = (1 / pos)*(total)/2.0
# Dicionário de pesos das classes para treinamento
class_weight = {0: weight_for_0, 1: weight_for_1}
print('Peso da classe 0: {:.2f}'.format(weight_for_0))
print('Peso da classe 1: {:.2f}'.format(weight_for_1))
Exemplos:
Total: 19673
Positivos: 10228 (51.99% do total)
Peso da classe 0: 1.04
Peso da classe 1: 0.96
[ ]:
input_shape = X_train.shape[1:]
input_features = Input(shape=input_shape, name='input_features')
x1 = Dense(128, activation='tanh', kernel_regularizer=l2())(input_features)
x2 = Dense(128, activation='selu', kernel_regularizer=l2())(input_features)
x3 = Dense(128, activation='sigmoid', kernel_regularizer=l2())(input_features)
from tensorflow.keras.layers import Concatenate
x_concat = Concatenate()([x1, x2, x3, input_features])
x4 = Dense(32, activation='relu', kernel_regularizer=l2())(x_concat)
out = Dense(1, activation='sigmoid', name='out_dense')(x4)
model = keras.Model(inputs=[input_features],
outputs=[out])
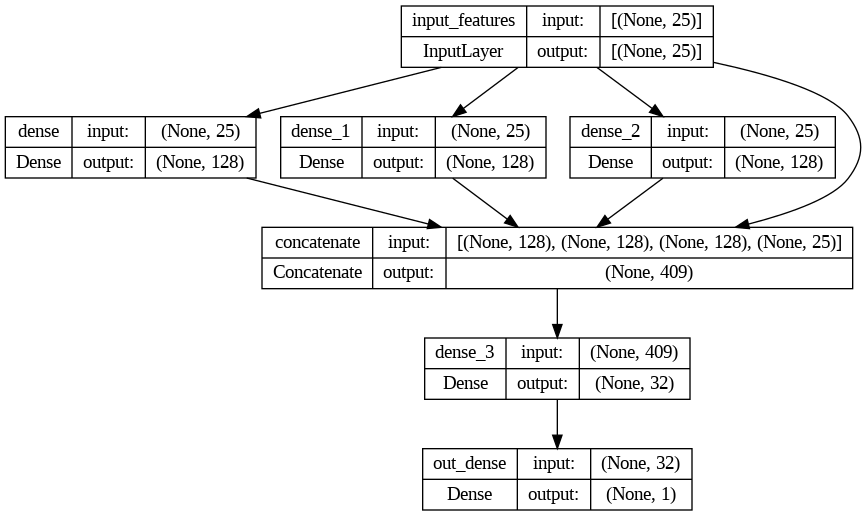
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_features (InputLayer) [(None, 25)] 0 []
dense (Dense) (None, 128) 3328 ['input_features[0][0]']
dense_1 (Dense) (None, 128) 3328 ['input_features[0][0]']
dense_2 (Dense) (None, 128) 3328 ['input_features[0][0]']
concatenate (Concatenate) (None, 409) 0 ['dense[0][0]',
'dense_1[0][0]',
'dense_2[0][0]',
'input_features[0][0]']
dense_3 (Dense) (None, 32) 13120 ['concatenate[0][0]']
out_dense (Dense) (None, 1) 33 ['dense_3[0][0]']
==================================================================================================
Total params: 23,137
Trainable params: 23,137
Non-trainable params: 0
__________________________________________________________________________________________________
[ ]:
keras.utils.plot_model(model, show_shapes=True)
[ ]:
from tensorflow.keras.callbacks import EarlyStopping
# Define métricas
METRICS = [keras.metrics.BinaryAccuracy(name='accuracy'),
keras.metrics.Precision(name='precision'),
keras.metrics.Recall(name='recall'),
keras.metrics.AUC(name='auc')]
call_es = EarlyStopping(monitor='val_loss', patience=20, restore_best_weights=True)
adam = Adam(learning_rate=0.001)
model.compile(optimizer=adam, loss='binary_crossentropy',
metrics=METRICS)
history = model.fit(X_train, y_train, epochs=50,
class_weight=class_weight,
verbose=2, batch_size=32,
validation_data=(X_test, y_test),
callbacks=[call_es])
Epoch 1/50
615/615 - 3s - loss: 0.9070 - accuracy: 0.7264 - precision: 0.7255 - recall: 0.7620 - auc: 0.7943 - val_loss: 0.6015 - val_accuracy: 0.7202 - val_precision: 0.6904 - val_recall: 0.8372 - val_auc: 0.7865 - 3s/epoch - 5ms/step
Epoch 2/50
615/615 - 1s - loss: 0.5670 - accuracy: 0.7321 - precision: 0.7277 - recall: 0.7744 - auc: 0.8010 - val_loss: 0.5706 - val_accuracy: 0.7231 - val_precision: 0.6949 - val_recall: 0.8334 - val_auc: 0.7924 - 1s/epoch - 2ms/step
Epoch 3/50
615/615 - 1s - loss: 0.5553 - accuracy: 0.7349 - precision: 0.7290 - recall: 0.7800 - auc: 0.8043 - val_loss: 0.5685 - val_accuracy: 0.7220 - val_precision: 0.7287 - val_recall: 0.7413 - val_auc: 0.7921 - 1s/epoch - 2ms/step
Epoch 4/50
615/615 - 1s - loss: 0.5504 - accuracy: 0.7392 - precision: 0.7324 - recall: 0.7855 - auc: 0.8072 - val_loss: 0.5644 - val_accuracy: 0.7255 - val_precision: 0.7008 - val_recall: 0.8238 - val_auc: 0.7947 - 1s/epoch - 2ms/step
Epoch 5/50
615/615 - 2s - loss: 0.5482 - accuracy: 0.7378 - precision: 0.7293 - recall: 0.7880 - auc: 0.8094 - val_loss: 0.5644 - val_accuracy: 0.7245 - val_precision: 0.7276 - val_recall: 0.7513 - val_auc: 0.7945 - 2s/epoch - 3ms/step
Epoch 6/50
615/615 - 2s - loss: 0.5460 - accuracy: 0.7428 - precision: 0.7354 - recall: 0.7892 - auc: 0.8113 - val_loss: 0.5684 - val_accuracy: 0.7242 - val_precision: 0.7437 - val_recall: 0.7164 - val_auc: 0.7977 - 2s/epoch - 3ms/step
Epoch 7/50
615/615 - 1s - loss: 0.5438 - accuracy: 0.7427 - precision: 0.7360 - recall: 0.7876 - auc: 0.8134 - val_loss: 0.5598 - val_accuracy: 0.7304 - val_precision: 0.7388 - val_recall: 0.7449 - val_auc: 0.8007 - 1s/epoch - 2ms/step
Epoch 8/50
615/615 - 1s - loss: 0.5438 - accuracy: 0.7436 - precision: 0.7380 - recall: 0.7856 - auc: 0.8133 - val_loss: 0.5543 - val_accuracy: 0.7325 - val_precision: 0.7164 - val_recall: 0.8038 - val_auc: 0.8007 - 1s/epoch - 2ms/step
Epoch 9/50
615/615 - 1s - loss: 0.5419 - accuracy: 0.7444 - precision: 0.7362 - recall: 0.7921 - auc: 0.8140 - val_loss: 0.5552 - val_accuracy: 0.7341 - val_precision: 0.7108 - val_recall: 0.8238 - val_auc: 0.8011 - 1s/epoch - 2ms/step
Epoch 10/50
615/615 - 1s - loss: 0.5382 - accuracy: 0.7463 - precision: 0.7395 - recall: 0.7904 - auc: 0.8175 - val_loss: 0.5621 - val_accuracy: 0.7281 - val_precision: 0.7441 - val_recall: 0.7273 - val_auc: 0.7999 - 1s/epoch - 2ms/step
Epoch 11/50
615/615 - 1s - loss: 0.5355 - accuracy: 0.7455 - precision: 0.7384 - recall: 0.7908 - auc: 0.8186 - val_loss: 0.5568 - val_accuracy: 0.7310 - val_precision: 0.7119 - val_recall: 0.8109 - val_auc: 0.7984 - 1s/epoch - 2ms/step
Epoch 12/50
615/615 - 1s - loss: 0.5368 - accuracy: 0.7463 - precision: 0.7390 - recall: 0.7917 - auc: 0.8180 - val_loss: 0.5591 - val_accuracy: 0.7303 - val_precision: 0.7417 - val_recall: 0.7384 - val_auc: 0.7997 - 1s/epoch - 2ms/step
Epoch 13/50
615/615 - 1s - loss: 0.5359 - accuracy: 0.7478 - precision: 0.7426 - recall: 0.7880 - auc: 0.8182 - val_loss: 0.5513 - val_accuracy: 0.7360 - val_precision: 0.7124 - val_recall: 0.8258 - val_auc: 0.8035 - 1s/epoch - 2ms/step
Epoch 14/50
615/615 - 1s - loss: 0.5341 - accuracy: 0.7469 - precision: 0.7412 - recall: 0.7884 - auc: 0.8194 - val_loss: 0.5487 - val_accuracy: 0.7342 - val_precision: 0.7277 - val_recall: 0.7812 - val_auc: 0.8054 - 1s/epoch - 2ms/step
Epoch 15/50
615/615 - 2s - loss: 0.5323 - accuracy: 0.7499 - precision: 0.7425 - recall: 0.7944 - auc: 0.8206 - val_loss: 0.5556 - val_accuracy: 0.7286 - val_precision: 0.7424 - val_recall: 0.7320 - val_auc: 0.8035 - 2s/epoch - 3ms/step
Epoch 16/50
615/615 - 1s - loss: 0.5320 - accuracy: 0.7503 - precision: 0.7420 - recall: 0.7967 - auc: 0.8208 - val_loss: 0.5506 - val_accuracy: 0.7357 - val_precision: 0.7244 - val_recall: 0.7938 - val_auc: 0.8044 - 1s/epoch - 2ms/step
Epoch 17/50
615/615 - 1s - loss: 0.5339 - accuracy: 0.7496 - precision: 0.7424 - recall: 0.7937 - auc: 0.8192 - val_loss: 0.5522 - val_accuracy: 0.7336 - val_precision: 0.7354 - val_recall: 0.7619 - val_auc: 0.8050 - 1s/epoch - 2ms/step
Epoch 18/50
615/615 - 1s - loss: 0.5301 - accuracy: 0.7502 - precision: 0.7416 - recall: 0.7972 - auc: 0.8219 - val_loss: 0.5503 - val_accuracy: 0.7336 - val_precision: 0.7376 - val_recall: 0.7569 - val_auc: 0.8050 - 1s/epoch - 2ms/step
Epoch 19/50
615/615 - 1s - loss: 0.5295 - accuracy: 0.7510 - precision: 0.7437 - recall: 0.7951 - auc: 0.8221 - val_loss: 0.5510 - val_accuracy: 0.7301 - val_precision: 0.7229 - val_recall: 0.7798 - val_auc: 0.8016 - 1s/epoch - 2ms/step
Epoch 20/50
615/615 - 1s - loss: 0.5295 - accuracy: 0.7497 - precision: 0.7426 - recall: 0.7937 - auc: 0.8222 - val_loss: 0.5493 - val_accuracy: 0.7312 - val_precision: 0.7062 - val_recall: 0.8270 - val_auc: 0.8044 - 1s/epoch - 2ms/step
Epoch 21/50
615/615 - 1s - loss: 0.5277 - accuracy: 0.7503 - precision: 0.7421 - recall: 0.7964 - auc: 0.8236 - val_loss: 0.5507 - val_accuracy: 0.7335 - val_precision: 0.7427 - val_recall: 0.7457 - val_auc: 0.8062 - 1s/epoch - 2ms/step
Epoch 22/50
615/615 - 1s - loss: 0.5273 - accuracy: 0.7507 - precision: 0.7437 - recall: 0.7943 - auc: 0.8240 - val_loss: 0.5453 - val_accuracy: 0.7354 - val_precision: 0.7230 - val_recall: 0.7962 - val_auc: 0.8066 - 1s/epoch - 2ms/step
Epoch 23/50
615/615 - 1s - loss: 0.5275 - accuracy: 0.7532 - precision: 0.7454 - recall: 0.7979 - auc: 0.8238 - val_loss: 0.5472 - val_accuracy: 0.7365 - val_precision: 0.7310 - val_recall: 0.7804 - val_auc: 0.8062 - 1s/epoch - 2ms/step
Epoch 24/50
615/615 - 2s - loss: 0.5259 - accuracy: 0.7520 - precision: 0.7440 - recall: 0.7972 - auc: 0.8245 - val_loss: 0.5490 - val_accuracy: 0.7350 - val_precision: 0.7272 - val_recall: 0.7848 - val_auc: 0.8049 - 2s/epoch - 3ms/step
Epoch 25/50
615/615 - 2s - loss: 0.5249 - accuracy: 0.7517 - precision: 0.7446 - recall: 0.7952 - auc: 0.8250 - val_loss: 0.5471 - val_accuracy: 0.7316 - val_precision: 0.7329 - val_recall: 0.7613 - val_auc: 0.8065 - 2s/epoch - 3ms/step
Epoch 26/50
615/615 - 1s - loss: 0.5254 - accuracy: 0.7524 - precision: 0.7440 - recall: 0.7984 - auc: 0.8244 - val_loss: 0.5522 - val_accuracy: 0.7301 - val_precision: 0.7413 - val_recall: 0.7387 - val_auc: 0.8060 - 1s/epoch - 2ms/step
Epoch 27/50
615/615 - 1s - loss: 0.5259 - accuracy: 0.7528 - precision: 0.7448 - recall: 0.7978 - auc: 0.8244 - val_loss: 0.5495 - val_accuracy: 0.7322 - val_precision: 0.7414 - val_recall: 0.7449 - val_auc: 0.8060 - 1s/epoch - 2ms/step
Epoch 28/50
615/615 - 1s - loss: 0.5234 - accuracy: 0.7536 - precision: 0.7457 - recall: 0.7982 - auc: 0.8263 - val_loss: 0.5457 - val_accuracy: 0.7388 - val_precision: 0.7268 - val_recall: 0.7974 - val_auc: 0.8060 - 1s/epoch - 2ms/step
Epoch 29/50
615/615 - 1s - loss: 0.5228 - accuracy: 0.7537 - precision: 0.7465 - recall: 0.7968 - auc: 0.8263 - val_loss: 0.5497 - val_accuracy: 0.7339 - val_precision: 0.7415 - val_recall: 0.7496 - val_auc: 0.8075 - 1s/epoch - 2ms/step
Epoch 30/50
615/615 - 1s - loss: 0.5236 - accuracy: 0.7545 - precision: 0.7462 - recall: 0.7999 - auc: 0.8264 - val_loss: 0.5531 - val_accuracy: 0.7306 - val_precision: 0.7065 - val_recall: 0.8243 - val_auc: 0.8057 - 1s/epoch - 2ms/step
Epoch 31/50
615/615 - 1s - loss: 0.5230 - accuracy: 0.7535 - precision: 0.7464 - recall: 0.7965 - auc: 0.8262 - val_loss: 0.5500 - val_accuracy: 0.7356 - val_precision: 0.7379 - val_recall: 0.7622 - val_auc: 0.8051 - 1s/epoch - 2ms/step
Epoch 32/50
615/615 - 1s - loss: 0.5197 - accuracy: 0.7544 - precision: 0.7471 - recall: 0.7977 - auc: 0.8280 - val_loss: 0.5529 - val_accuracy: 0.7301 - val_precision: 0.7440 - val_recall: 0.7331 - val_auc: 0.8049 - 1s/epoch - 2ms/step
Epoch 33/50
615/615 - 1s - loss: 0.5213 - accuracy: 0.7564 - precision: 0.7477 - recall: 0.8019 - auc: 0.8271 - val_loss: 0.5444 - val_accuracy: 0.7330 - val_precision: 0.7286 - val_recall: 0.7754 - val_auc: 0.8062 - 1s/epoch - 2ms/step
Epoch 34/50
615/615 - 2s - loss: 0.5214 - accuracy: 0.7571 - precision: 0.7471 - recall: 0.8053 - auc: 0.8269 - val_loss: 0.5462 - val_accuracy: 0.7379 - val_precision: 0.7183 - val_recall: 0.8158 - val_auc: 0.8049 - 2s/epoch - 3ms/step
Epoch 35/50
615/615 - 1s - loss: 0.5226 - accuracy: 0.7558 - precision: 0.7476 - recall: 0.8005 - auc: 0.8265 - val_loss: 0.5413 - val_accuracy: 0.7365 - val_precision: 0.7316 - val_recall: 0.7792 - val_auc: 0.8087 - 1s/epoch - 2ms/step
Epoch 36/50
615/615 - 1s - loss: 0.5196 - accuracy: 0.7557 - precision: 0.7471 - recall: 0.8014 - auc: 0.8276 - val_loss: 0.5440 - val_accuracy: 0.7385 - val_precision: 0.7237 - val_recall: 0.8041 - val_auc: 0.8078 - 1s/epoch - 2ms/step
Epoch 37/50
615/615 - 1s - loss: 0.5210 - accuracy: 0.7554 - precision: 0.7474 - recall: 0.7999 - auc: 0.8276 - val_loss: 0.5450 - val_accuracy: 0.7350 - val_precision: 0.7293 - val_recall: 0.7798 - val_auc: 0.8065 - 1s/epoch - 2ms/step
Epoch 38/50
615/615 - 1s - loss: 0.5203 - accuracy: 0.7587 - precision: 0.7497 - recall: 0.8044 - auc: 0.8278 - val_loss: 0.5428 - val_accuracy: 0.7354 - val_precision: 0.7242 - val_recall: 0.7933 - val_auc: 0.8073 - 1s/epoch - 2ms/step
Epoch 39/50
615/615 - 1s - loss: 0.5190 - accuracy: 0.7555 - precision: 0.7459 - recall: 0.8032 - auc: 0.8281 - val_loss: 0.5468 - val_accuracy: 0.7321 - val_precision: 0.7326 - val_recall: 0.7633 - val_auc: 0.8053 - 1s/epoch - 2ms/step
Epoch 40/50
615/615 - 1s - loss: 0.5205 - accuracy: 0.7541 - precision: 0.7454 - recall: 0.8005 - auc: 0.8276 - val_loss: 0.5446 - val_accuracy: 0.7365 - val_precision: 0.7384 - val_recall: 0.7639 - val_auc: 0.8086 - 1s/epoch - 2ms/step
Epoch 41/50
615/615 - 1s - loss: 0.5200 - accuracy: 0.7546 - precision: 0.7454 - recall: 0.8018 - auc: 0.8273 - val_loss: 0.5502 - val_accuracy: 0.7371 - val_precision: 0.7236 - val_recall: 0.8000 - val_auc: 0.8039 - 1s/epoch - 2ms/step
Epoch 42/50
615/615 - 2s - loss: 0.5188 - accuracy: 0.7570 - precision: 0.7470 - recall: 0.8054 - auc: 0.8285 - val_loss: 0.5433 - val_accuracy: 0.7374 - val_precision: 0.7331 - val_recall: 0.7783 - val_auc: 0.8071 - 2s/epoch - 3ms/step
Epoch 43/50
615/615 - 2s - loss: 0.5182 - accuracy: 0.7538 - precision: 0.7453 - recall: 0.7998 - auc: 0.8284 - val_loss: 0.5416 - val_accuracy: 0.7371 - val_precision: 0.7230 - val_recall: 0.8015 - val_auc: 0.8085 - 2s/epoch - 3ms/step
Epoch 44/50
615/615 - 1s - loss: 0.5194 - accuracy: 0.7574 - precision: 0.7473 - recall: 0.8059 - auc: 0.8287 - val_loss: 0.5413 - val_accuracy: 0.7368 - val_precision: 0.7219 - val_recall: 0.8032 - val_auc: 0.8090 - 1s/epoch - 2ms/step
Epoch 45/50
615/615 - 1s - loss: 0.5176 - accuracy: 0.7550 - precision: 0.7463 - recall: 0.8011 - auc: 0.8289 - val_loss: 0.5450 - val_accuracy: 0.7374 - val_precision: 0.7207 - val_recall: 0.8082 - val_auc: 0.8063 - 1s/epoch - 2ms/step
Epoch 46/50
615/615 - 1s - loss: 0.5176 - accuracy: 0.7565 - precision: 0.7482 - recall: 0.8013 - auc: 0.8295 - val_loss: 0.5396 - val_accuracy: 0.7353 - val_precision: 0.7267 - val_recall: 0.7868 - val_auc: 0.8092 - 1s/epoch - 2ms/step
Epoch 47/50
615/615 - 1s - loss: 0.5179 - accuracy: 0.7556 - precision: 0.7471 - recall: 0.8010 - auc: 0.8288 - val_loss: 0.5420 - val_accuracy: 0.7376 - val_precision: 0.7319 - val_recall: 0.7815 - val_auc: 0.8102 - 1s/epoch - 2ms/step
Epoch 48/50
615/615 - 1s - loss: 0.5199 - accuracy: 0.7551 - precision: 0.7470 - recall: 0.7999 - auc: 0.8283 - val_loss: 0.5409 - val_accuracy: 0.7389 - val_precision: 0.7270 - val_recall: 0.7974 - val_auc: 0.8085 - 1s/epoch - 2ms/step
Epoch 49/50
615/615 - 1s - loss: 0.5177 - accuracy: 0.7555 - precision: 0.7465 - recall: 0.8021 - auc: 0.8290 - val_loss: 0.5470 - val_accuracy: 0.7318 - val_precision: 0.7309 - val_recall: 0.7663 - val_auc: 0.8058 - 1s/epoch - 2ms/step
Epoch 50/50
615/615 - 1s - loss: 0.5177 - accuracy: 0.7570 - precision: 0.7475 - recall: 0.8043 - auc: 0.8294 - val_loss: 0.5411 - val_accuracy: 0.7357 - val_precision: 0.7233 - val_recall: 0.7965 - val_auc: 0.8082 - 1s/epoch - 2ms/step
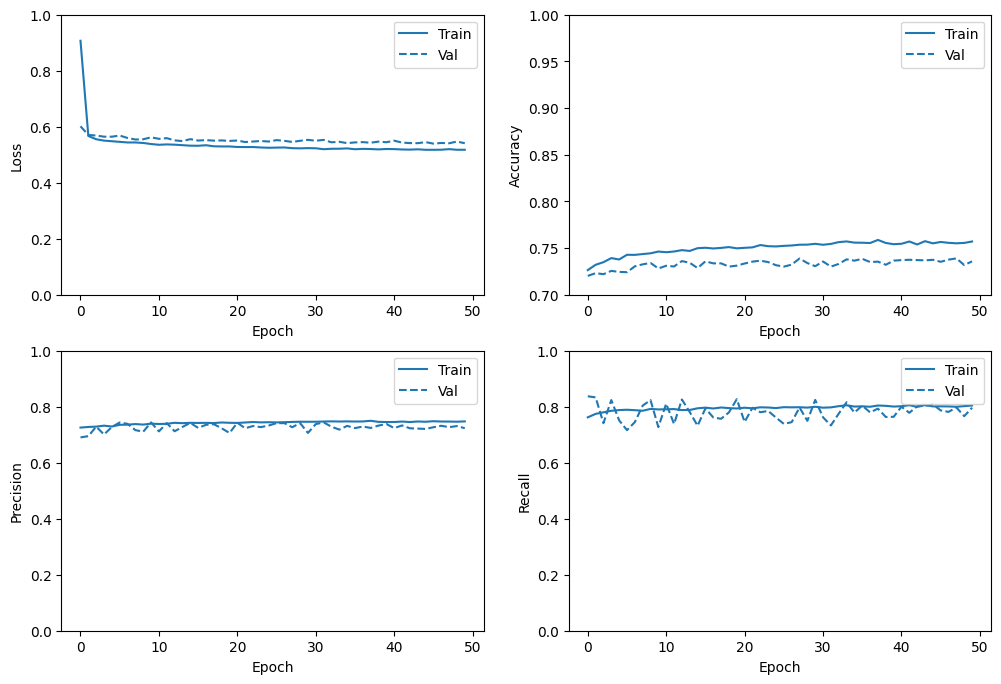
Resultados
[ ]:
plot_metrics(history)
[ ]:
train_pred = model.predict(X_train)
test_pred = model.predict(X_test)
print('Número de exemplos positivos do conjunto de teste =', len(y_test[y_test > 0.9]))
results = model.evaluate(X_test, y_test, verbose=0)
for name, value in zip(model.metrics_names, results):
print(f'{name}: {value:.4f}')
615/615 [==============================] - 1s 1ms/step
205/205 [==============================] - 0s 1ms/step
Número de exemplos positivos do conjunto de teste = 3410
loss: 0.5411
accuracy: 0.7357
precision: 0.7233
recall: 0.7965
auc: 0.8082
[ ]:
precision = results[2]
recall = results[3]
F1 = 2*precision*recall/(precision + recall)
print(f'Pontuação F1 = {F1:.4f}')
Pontuação F1 = 0.7581
[ ]:
ConfusionMatrixDisplay.from_predictions(y_test, np.round(test_pred),
normalize='true', cmap='Blues',
values_format='.3f')
plt.show()
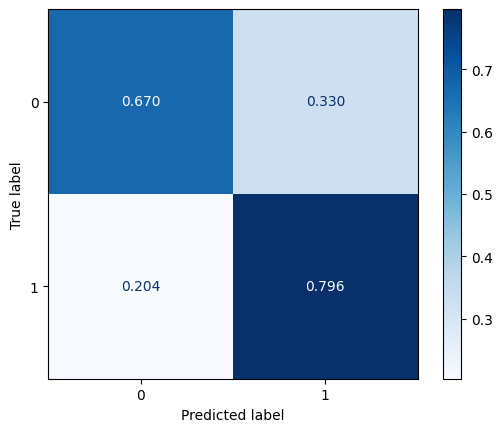
[ ]:
from sklearn.metrics import balanced_accuracy_score
balanced_accuracy_score(y_test, np.round(test_pred))
0.7332150562476012
[ ]:
fp_train, tp_train, _ = roc_curve(y_train, train_pred)
fp_test, tp_test, _ = roc_curve(y_test, test_pred)
plt.figure(figsize=(8, 6))
plt.plot(100*fp_train, 100*tp_train, 'b', label='Dados treinamento')
plt.plot(100*fp_test, 100*tp_test, 'r', label='Dados teste')
plt.xlabel('Positivos falsos [%]')
plt.ylabel('Positivos verdadeiros [%]')
plt.xlim([0,100])
plt.ylim([0,100])
plt.grid(True)
plt.legend()
plt.show()
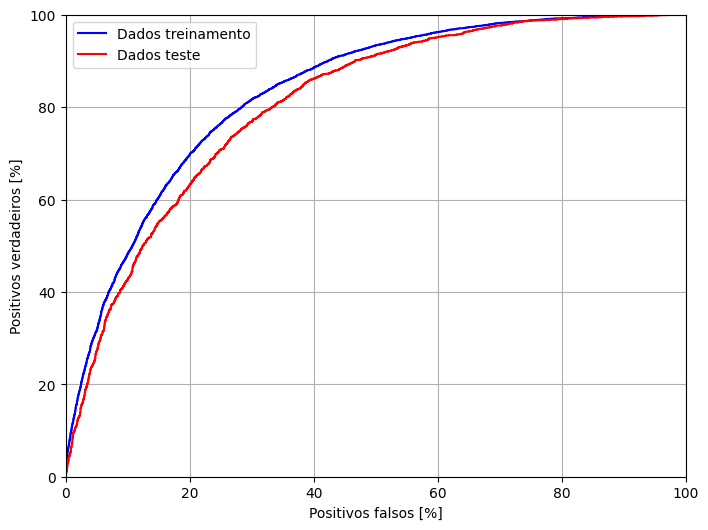
[ ]:
custo_e_metricas_train = model.evaluate(X_train, y_train)
# custo_e_metricas_val = rna_reg.evaluate(X_val_norm, y_val)
custo_e_metricas_test = model.evaluate(X_test, y_test)
615/615 [==============================] - 1s 2ms/step - loss: 0.5118 - accuracy: 0.7608 - precision: 0.7467 - recall: 0.8170 - auc: 0.8331
205/205 [==============================] - 0s 1ms/step - loss: 0.5411 - accuracy: 0.7357 - precision: 0.7233 - recall: 0.7965 - auc: 0.8082
Criação e treinamento da RNA Residual
[ ]:
# Função que cria o bloco para a RN residual
def bloco_residual(x, n):
z1 = Dense(n, activation='relu')(x)
z2 = Dense(n)(z1)
sum = Add()([x, z2])
a2 = Activation('relu')(sum)
return a2
[ ]:
# Definição da entrada
input_shape = X_train.shape[1:]
input_features = Input(shape=input_shape)
X1 = Dense(64, activation='relu')(input_features)
X2 = bloco_residual(X1, 64)
X3 = Dense(64, activation='relu')(X2)
X4 = bloco_residual(X3, 64)
X5 = Dense(16, activation='relu')(X4)
Y = Dense(units=1, activation='sigmoid')(X5)
# Criação da RNA
rna = Model(input_features, Y)
# Mostra resumo da RNA
rna.summary()
Model: "model_1"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 25)] 0 []
dense_4 (Dense) (None, 64) 1664 ['input_1[0][0]']
dense_5 (Dense) (None, 64) 4160 ['dense_4[0][0]']
dense_6 (Dense) (None, 64) 4160 ['dense_5[0][0]']
add (Add) (None, 64) 0 ['dense_4[0][0]',
'dense_6[0][0]']
activation (Activation) (None, 64) 0 ['add[0][0]']
dense_7 (Dense) (None, 64) 4160 ['activation[0][0]']
dense_8 (Dense) (None, 64) 4160 ['dense_7[0][0]']
dense_9 (Dense) (None, 64) 4160 ['dense_8[0][0]']
add_1 (Add) (None, 64) 0 ['dense_7[0][0]',
'dense_9[0][0]']
activation_1 (Activation) (None, 64) 0 ['add_1[0][0]']
dense_10 (Dense) (None, 16) 1040 ['activation_1[0][0]']
dense_11 (Dense) (None, 1) 17 ['dense_10[0][0]']
==================================================================================================
Total params: 23,521
Trainable params: 23,521
Non-trainable params: 0
__________________________________________________________________________________________________
[ ]:
keras.utils.plot_model(rna, show_shapes=True)
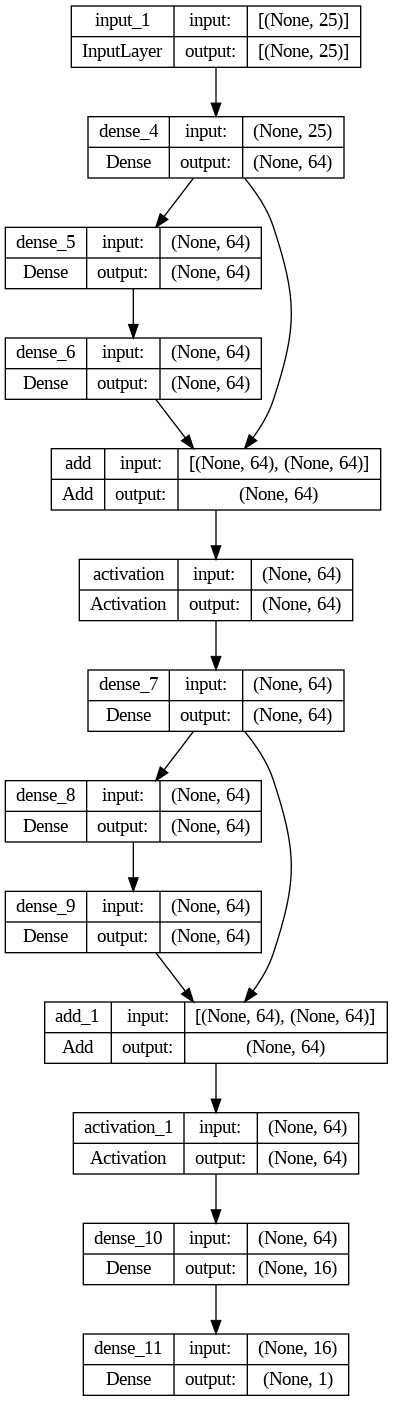
[ ]:
from tensorflow.keras.callbacks import EarlyStopping
# Define métricas
METRICS = [keras.metrics.BinaryAccuracy(name='accuracy'),
keras.metrics.Precision(name='precision'),
keras.metrics.Recall(name='recall'),
keras.metrics.AUC(name='auc')]
call_es = EarlyStopping(monitor='val_loss', patience=20,
restore_best_weights=True)
adam = Adam(learning_rate=0.001)
rna.compile(optimizer=adam, loss='binary_crossentropy',
metrics=METRICS)
history = rna.fit(X_train, y_train, epochs=50,
class_weight=class_weight,
verbose=2, batch_size=32,
validation_data=(X_test, y_test),
callbacks=[call_es])
Epoch 1/50
615/615 - 4s - loss: 0.5493 - accuracy: 0.7272 - precision: 0.7269 - recall: 0.7615 - auc: 0.7946 - val_loss: 0.5440 - val_accuracy: 0.7252 - val_precision: 0.7031 - val_recall: 0.8161 - val_auc: 0.7949 - 4s/epoch - 6ms/step
Epoch 2/50
615/615 - 1s - loss: 0.5181 - accuracy: 0.7469 - precision: 0.7402 - recall: 0.7907 - auc: 0.8193 - val_loss: 0.5369 - val_accuracy: 0.7240 - val_precision: 0.7320 - val_recall: 0.7402 - val_auc: 0.8037 - 1s/epoch - 2ms/step
Epoch 3/50
615/615 - 1s - loss: 0.5081 - accuracy: 0.7516 - precision: 0.7474 - recall: 0.7890 - auc: 0.8272 - val_loss: 0.5449 - val_accuracy: 0.7237 - val_precision: 0.7511 - val_recall: 0.7009 - val_auc: 0.8070 - 1s/epoch - 2ms/step
Epoch 4/50
615/615 - 1s - loss: 0.4998 - accuracy: 0.7589 - precision: 0.7553 - recall: 0.7933 - auc: 0.8334 - val_loss: 0.5400 - val_accuracy: 0.7290 - val_precision: 0.7418 - val_recall: 0.7346 - val_auc: 0.8077 - 1s/epoch - 2ms/step
Epoch 5/50
615/615 - 1s - loss: 0.4957 - accuracy: 0.7623 - precision: 0.7552 - recall: 0.8031 - auc: 0.8365 - val_loss: 0.5497 - val_accuracy: 0.7274 - val_precision: 0.7374 - val_recall: 0.7387 - val_auc: 0.8042 - 1s/epoch - 2ms/step
Epoch 6/50
615/615 - 1s - loss: 0.4891 - accuracy: 0.7649 - precision: 0.7617 - recall: 0.7971 - auc: 0.8414 - val_loss: 0.5521 - val_accuracy: 0.7328 - val_precision: 0.7363 - val_recall: 0.7575 - val_auc: 0.8041 - 1s/epoch - 2ms/step
Epoch 7/50
615/615 - 1s - loss: 0.4841 - accuracy: 0.7698 - precision: 0.7656 - recall: 0.8032 - auc: 0.8455 - val_loss: 0.5378 - val_accuracy: 0.7330 - val_precision: 0.7409 - val_recall: 0.7481 - val_auc: 0.8078 - 1s/epoch - 2ms/step
Epoch 8/50
615/615 - 2s - loss: 0.4778 - accuracy: 0.7705 - precision: 0.7700 - recall: 0.7964 - auc: 0.8495 - val_loss: 0.5402 - val_accuracy: 0.7321 - val_precision: 0.7228 - val_recall: 0.7862 - val_auc: 0.8044 - 2s/epoch - 3ms/step
Epoch 9/50
615/615 - 2s - loss: 0.4719 - accuracy: 0.7753 - precision: 0.7729 - recall: 0.8041 - auc: 0.8537 - val_loss: 0.5342 - val_accuracy: 0.7348 - val_precision: 0.7152 - val_recall: 0.8144 - val_auc: 0.8051 - 2s/epoch - 4ms/step
Epoch 10/50
615/615 - 1s - loss: 0.4666 - accuracy: 0.7777 - precision: 0.7752 - recall: 0.8061 - auc: 0.8573 - val_loss: 0.5562 - val_accuracy: 0.7303 - val_precision: 0.7400 - val_recall: 0.7419 - val_auc: 0.8051 - 1s/epoch - 2ms/step
Epoch 11/50
615/615 - 1s - loss: 0.4590 - accuracy: 0.7814 - precision: 0.7812 - recall: 0.8051 - auc: 0.8624 - val_loss: 0.5642 - val_accuracy: 0.7289 - val_precision: 0.7269 - val_recall: 0.7666 - val_auc: 0.7993 - 1s/epoch - 2ms/step
Epoch 12/50
615/615 - 1s - loss: 0.4542 - accuracy: 0.7853 - precision: 0.7846 - recall: 0.8092 - auc: 0.8654 - val_loss: 0.5485 - val_accuracy: 0.7248 - val_precision: 0.7269 - val_recall: 0.7540 - val_auc: 0.8007 - 1s/epoch - 2ms/step
Epoch 13/50
615/615 - 1s - loss: 0.4466 - accuracy: 0.7887 - precision: 0.7868 - recall: 0.8142 - auc: 0.8703 - val_loss: 0.5550 - val_accuracy: 0.7255 - val_precision: 0.7176 - val_recall: 0.7786 - val_auc: 0.7965 - 1s/epoch - 2ms/step
Epoch 14/50
615/615 - 1s - loss: 0.4371 - accuracy: 0.7970 - precision: 0.7959 - recall: 0.8197 - auc: 0.8762 - val_loss: 0.5788 - val_accuracy: 0.7246 - val_precision: 0.7394 - val_recall: 0.7264 - val_auc: 0.7977 - 1s/epoch - 2ms/step
Epoch 15/50
615/615 - 1s - loss: 0.4307 - accuracy: 0.7969 - precision: 0.7970 - recall: 0.8178 - auc: 0.8801 - val_loss: 0.5627 - val_accuracy: 0.7251 - val_precision: 0.7281 - val_recall: 0.7522 - val_auc: 0.7970 - 1s/epoch - 2ms/step
Epoch 16/50
615/615 - 1s - loss: 0.4212 - accuracy: 0.8019 - precision: 0.8033 - recall: 0.8197 - auc: 0.8859 - val_loss: 0.5813 - val_accuracy: 0.7156 - val_precision: 0.7382 - val_recall: 0.7021 - val_auc: 0.7943 - 1s/epoch - 2ms/step
Epoch 17/50
615/615 - 2s - loss: 0.4155 - accuracy: 0.8088 - precision: 0.8075 - recall: 0.8302 - auc: 0.8889 - val_loss: 0.5799 - val_accuracy: 0.7203 - val_precision: 0.7176 - val_recall: 0.7622 - val_auc: 0.7896 - 2s/epoch - 3ms/step
Epoch 18/50
615/615 - 2s - loss: 0.4060 - accuracy: 0.8111 - precision: 0.8115 - recall: 0.8292 - auc: 0.8948 - val_loss: 0.5944 - val_accuracy: 0.7196 - val_precision: 0.7228 - val_recall: 0.7472 - val_auc: 0.7865 - 2s/epoch - 3ms/step
Epoch 19/50
615/615 - 1s - loss: 0.3978 - accuracy: 0.8173 - precision: 0.8192 - recall: 0.8323 - auc: 0.8995 - val_loss: 0.6319 - val_accuracy: 0.7145 - val_precision: 0.7281 - val_recall: 0.7199 - val_auc: 0.7875 - 1s/epoch - 2ms/step
Epoch 20/50
615/615 - 1s - loss: 0.3902 - accuracy: 0.8199 - precision: 0.8195 - recall: 0.8383 - auc: 0.9032 - val_loss: 0.6097 - val_accuracy: 0.7132 - val_precision: 0.7068 - val_recall: 0.7663 - val_auc: 0.7834 - 1s/epoch - 2ms/step
Epoch 21/50
615/615 - 1s - loss: 0.3795 - accuracy: 0.8262 - precision: 0.8271 - recall: 0.8416 - auc: 0.9089 - val_loss: 0.6462 - val_accuracy: 0.7104 - val_precision: 0.7244 - val_recall: 0.7152 - val_auc: 0.7798 - 1s/epoch - 2ms/step
Epoch 22/50
615/615 - 1s - loss: 0.3706 - accuracy: 0.8323 - precision: 0.8349 - recall: 0.8443 - auc: 0.9133 - val_loss: 0.6584 - val_accuracy: 0.7132 - val_precision: 0.7127 - val_recall: 0.7513 - val_auc: 0.7800 - 1s/epoch - 2ms/step
Epoch 23/50
615/615 - 1s - loss: 0.3615 - accuracy: 0.8358 - precision: 0.8373 - recall: 0.8492 - auc: 0.9177 - val_loss: 0.6656 - val_accuracy: 0.7158 - val_precision: 0.7166 - val_recall: 0.7499 - val_auc: 0.7787 - 1s/epoch - 2ms/step
Epoch 24/50
615/615 - 1s - loss: 0.3484 - accuracy: 0.8405 - precision: 0.8451 - recall: 0.8489 - auc: 0.9239 - val_loss: 0.7124 - val_accuracy: 0.7162 - val_precision: 0.7219 - val_recall: 0.7390 - val_auc: 0.7805 - 1s/epoch - 2ms/step
Epoch 25/50
615/615 - 1s - loss: 0.3457 - accuracy: 0.8446 - precision: 0.8462 - recall: 0.8568 - auc: 0.9250 - val_loss: 0.6782 - val_accuracy: 0.7063 - val_precision: 0.7033 - val_recall: 0.7528 - val_auc: 0.7721 - 1s/epoch - 2ms/step
Epoch 26/50
615/615 - 2s - loss: 0.3346 - accuracy: 0.8478 - precision: 0.8512 - recall: 0.8572 - auc: 0.9299 - val_loss: 0.7104 - val_accuracy: 0.7031 - val_precision: 0.7150 - val_recall: 0.7135 - val_auc: 0.7697 - 2s/epoch - 3ms/step
Epoch 27/50
615/615 - 2s - loss: 0.3278 - accuracy: 0.8520 - precision: 0.8541 - recall: 0.8626 - auc: 0.9331 - val_loss: 0.7178 - val_accuracy: 0.7013 - val_precision: 0.7160 - val_recall: 0.7053 - val_auc: 0.7633 - 2s/epoch - 3ms/step
Epoch 28/50
615/615 - 1s - loss: 0.3189 - accuracy: 0.8562 - precision: 0.8599 - recall: 0.8642 - auc: 0.9364 - val_loss: 0.7461 - val_accuracy: 0.7106 - val_precision: 0.7101 - val_recall: 0.7493 - val_auc: 0.7704 - 1s/epoch - 2ms/step
Epoch 29/50
615/615 - 1s - loss: 0.3102 - accuracy: 0.8597 - precision: 0.8638 - recall: 0.8667 - auc: 0.9402 - val_loss: 0.7526 - val_accuracy: 0.6953 - val_precision: 0.7251 - val_recall: 0.6669 - val_auc: 0.7635 - 1s/epoch - 2ms/step
Resultados
[ ]:
plot_metrics(history)
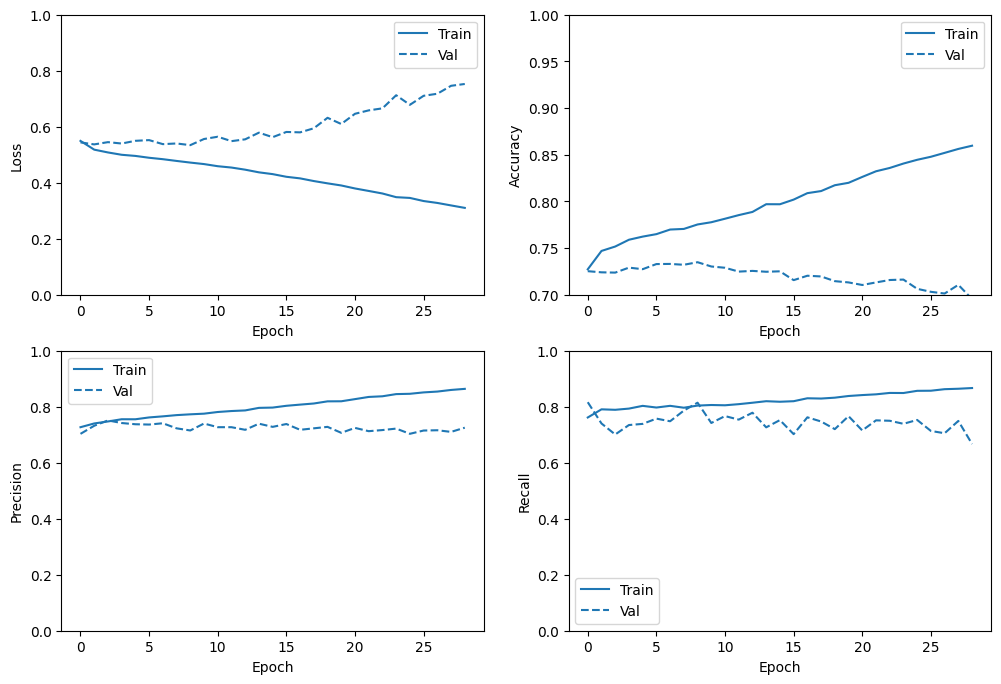
[ ]:
train_pred = rna.predict(X_train)
test_pred = rna.predict(X_test)
print('Número de exemplos positivos do conjunto de teste =', len(y_test[y_test > 0.9]))
results = rna.evaluate(X_test, y_test, verbose=0)
for name, value in zip(rna.metrics_names, results):
print(f'{name}: {value:.4f}')
615/615 [==============================] - 1s 1ms/step
205/205 [==============================] - 0s 1ms/step
Número de exemplos positivos do conjunto de teste = 3410
loss: 0.5342
accuracy: 0.7348
precision: 0.7152
recall: 0.8144
auc: 0.8051
[ ]:
precision = results[2]
recall = results[3]
F1 = 2*precision*recall/(precision + recall)
print(f'Pontuação F1 = {F1:.4f}')
Pontuação F1 = 0.7616
[ ]:
ConfusionMatrixDisplay.from_predictions(y_test, np.round(test_pred),
normalize='true', cmap='Blues',
values_format='.3f')
plt.show()
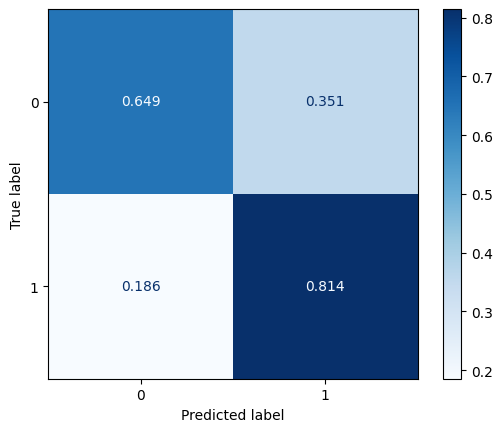
[ ]:
from sklearn.metrics import balanced_accuracy_score
balanced_accuracy_score(y_test, np.round(test_pred))
0.7315176605171276
[ ]:
fp_train, tp_train, _ = roc_curve(y_train, train_pred)
fp_test, tp_test, _ = roc_curve(y_test, test_pred)
plt.figure(figsize=(8, 6))
plt.plot(100*fp_train, 100*tp_train, 'b', label='Dados treinamento')
plt.plot(100*fp_test, 100*tp_test, 'r', label='Dados teste')
plt.xlabel('Positivos falsos [%]')
plt.ylabel('Positivos verdadeiros [%]')
plt.xlim([0,100])
plt.ylim([0,100])
plt.grid(True)
plt.legend()
plt.show()
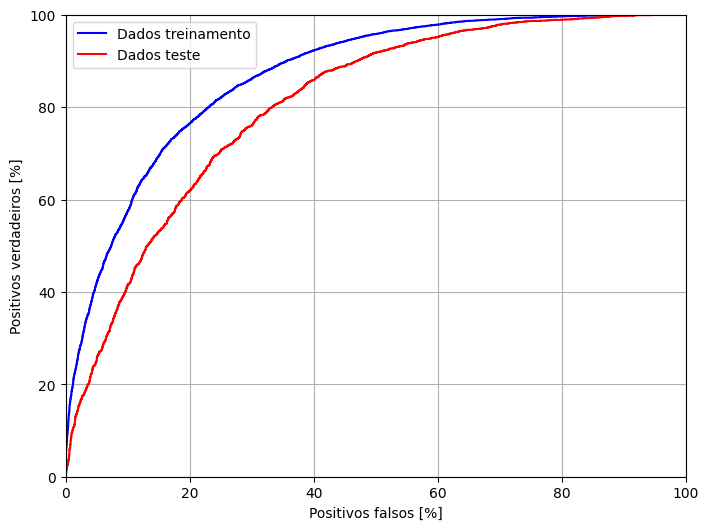
[ ]:
custo_e_metricas_train = rna.evaluate(X_train, y_train)
custo_e_metricas_test = rna.evaluate(X_test, y_test)
615/615 [==============================] - 1s 2ms/step - loss: 0.4551 - accuracy: 0.7840 - precision: 0.7575 - recall: 0.8598 - auc: 0.8678
205/205 [==============================] - 0s 2ms/step - loss: 0.5342 - accuracy: 0.7348 - precision: 0.7152 - recall: 0.8144 - auc: 0.8051
Criação e treinamento da RNA Sequencial
[ ]:
neg, pos = np.bincount(y_train)
total = neg + pos
print(f'Exemplos:\n Total: {total}\n Positivos: {pos} ({100*pos/total:.2f}% do total)')
# Cálculo dos pesos das duas classe
weight_for_0 = (1 / neg)*(total)/2.0
weight_for_1 = (1 / pos)*(total)/2.0
# Dicionário de pesos das classes para treinamento
class_weight = {0: weight_for_0, 1: weight_for_1}
print('Peso da classe 0: {:.2f}'.format(weight_for_0))
print('Peso da classe 1: {:.2f}'.format(weight_for_1))
Exemplos:
Total: 19673
Positivos: 10228 (51.99% do total)
Peso da classe 0: 1.04
Peso da classe 1: 0.96
[ ]:
rna = Sequential()
rna.add(Dense(units=128, activation='relu', input_shape=X_train.shape[1:]))
rna.add(Dense(units=128, activation='relu'))
rna.add(Dense(units=32, activation='relu'))
rna.add(Dense(units=1, activation='sigmoid'))
rna.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_12 (Dense) (None, 128) 3328
dense_13 (Dense) (None, 128) 16512
dense_14 (Dense) (None, 32) 4128
dense_15 (Dense) (None, 1) 33
=================================================================
Total params: 24,001
Trainable params: 24,001
Non-trainable params: 0
_________________________________________________________________
[ ]:
keras.utils.plot_model(rna, show_shapes=True)
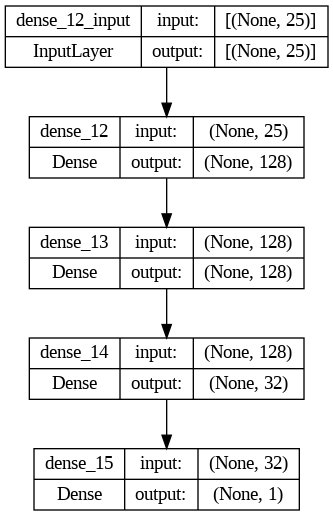
[ ]:
from tensorflow.keras.callbacks import EarlyStopping
# Define métricas
METRICS = [keras.metrics.BinaryAccuracy(name='accuracy'),
keras.metrics.Precision(name='precision'),
keras.metrics.Recall(name='recall'),
keras.metrics.AUC(name='auc')]
call_es = EarlyStopping(monitor='val_loss', patience=20,
restore_best_weights=True)
adam = Adam(learning_rate=0.001)
rna.compile(optimizer=adam, loss='binary_crossentropy',
metrics=METRICS)
history = rna.fit(X_train, y_train, epochs=50,
class_weight=class_weight,
verbose=2, batch_size=32,
validation_data=(X_test, y_test),
callbacks=[call_es])
Epoch 1/50
615/615 - 3s - loss: 0.5417 - accuracy: 0.7316 - precision: 0.7243 - recall: 0.7810 - auc: 0.7998 - val_loss: 0.5369 - val_accuracy: 0.7292 - val_precision: 0.7337 - val_recall: 0.7522 - val_auc: 0.8037 - 3s/epoch - 5ms/step
Epoch 2/50
615/615 - 1s - loss: 0.5155 - accuracy: 0.7491 - precision: 0.7459 - recall: 0.7847 - auc: 0.8218 - val_loss: 0.5332 - val_accuracy: 0.7309 - val_precision: 0.7103 - val_recall: 0.8147 - val_auc: 0.8049 - 1s/epoch - 2ms/step
Epoch 3/50
615/615 - 1s - loss: 0.5038 - accuracy: 0.7577 - precision: 0.7512 - recall: 0.7984 - auc: 0.8305 - val_loss: 0.5329 - val_accuracy: 0.7325 - val_precision: 0.7180 - val_recall: 0.7997 - val_auc: 0.8062 - 1s/epoch - 2ms/step
Epoch 4/50
615/615 - 2s - loss: 0.4978 - accuracy: 0.7603 - precision: 0.7534 - recall: 0.8012 - auc: 0.8347 - val_loss: 0.5324 - val_accuracy: 0.7322 - val_precision: 0.7127 - val_recall: 0.8126 - val_auc: 0.8055 - 2s/epoch - 3ms/step
Epoch 5/50
615/615 - 2s - loss: 0.4909 - accuracy: 0.7633 - precision: 0.7565 - recall: 0.8033 - auc: 0.8394 - val_loss: 0.5309 - val_accuracy: 0.7370 - val_precision: 0.7316 - val_recall: 0.7804 - val_auc: 0.8076 - 2s/epoch - 3ms/step
Epoch 6/50
615/615 - 1s - loss: 0.4850 - accuracy: 0.7669 - precision: 0.7598 - recall: 0.8067 - auc: 0.8437 - val_loss: 0.5401 - val_accuracy: 0.7341 - val_precision: 0.7226 - val_recall: 0.7930 - val_auc: 0.8062 - 1s/epoch - 2ms/step
Epoch 7/50
615/615 - 1s - loss: 0.4813 - accuracy: 0.7695 - precision: 0.7604 - recall: 0.8127 - auc: 0.8464 - val_loss: 0.5357 - val_accuracy: 0.7274 - val_precision: 0.7190 - val_recall: 0.7809 - val_auc: 0.8040 - 1s/epoch - 2ms/step
Epoch 8/50
615/615 - 1s - loss: 0.4749 - accuracy: 0.7750 - precision: 0.7676 - recall: 0.8136 - auc: 0.8505 - val_loss: 0.5284 - val_accuracy: 0.7335 - val_precision: 0.7296 - val_recall: 0.7745 - val_auc: 0.8097 - 1s/epoch - 2ms/step
Epoch 9/50
615/615 - 1s - loss: 0.4698 - accuracy: 0.7751 - precision: 0.7658 - recall: 0.8176 - auc: 0.8546 - val_loss: 0.5492 - val_accuracy: 0.7254 - val_precision: 0.7473 - val_recall: 0.7129 - val_auc: 0.8068 - 1s/epoch - 2ms/step
Epoch 10/50
615/615 - 1s - loss: 0.4641 - accuracy: 0.7796 - precision: 0.7717 - recall: 0.8181 - auc: 0.8583 - val_loss: 0.5413 - val_accuracy: 0.7309 - val_precision: 0.7273 - val_recall: 0.7718 - val_auc: 0.8118 - 1s/epoch - 2ms/step
Epoch 11/50
615/615 - 1s - loss: 0.4580 - accuracy: 0.7834 - precision: 0.7754 - recall: 0.8213 - auc: 0.8621 - val_loss: 0.5491 - val_accuracy: 0.7306 - val_precision: 0.7141 - val_recall: 0.8035 - val_auc: 0.8039 - 1s/epoch - 2ms/step
Epoch 12/50
615/615 - 1s - loss: 0.4524 - accuracy: 0.7863 - precision: 0.7778 - recall: 0.8244 - auc: 0.8661 - val_loss: 0.5411 - val_accuracy: 0.7328 - val_precision: 0.7176 - val_recall: 0.8018 - val_auc: 0.8009 - 1s/epoch - 2ms/step
Epoch 13/50
615/615 - 1s - loss: 0.4459 - accuracy: 0.7906 - precision: 0.7838 - recall: 0.8248 - auc: 0.8701 - val_loss: 0.5462 - val_accuracy: 0.7248 - val_precision: 0.7185 - val_recall: 0.7739 - val_auc: 0.8012 - 1s/epoch - 2ms/step
Epoch 14/50
615/615 - 2s - loss: 0.4374 - accuracy: 0.7941 - precision: 0.7858 - recall: 0.8304 - auc: 0.8756 - val_loss: 0.5519 - val_accuracy: 0.7313 - val_precision: 0.7142 - val_recall: 0.8056 - val_auc: 0.8013 - 2s/epoch - 3ms/step
Epoch 15/50
615/615 - 2s - loss: 0.4327 - accuracy: 0.7975 - precision: 0.7877 - recall: 0.8357 - auc: 0.8783 - val_loss: 0.5595 - val_accuracy: 0.7295 - val_precision: 0.7349 - val_recall: 0.7504 - val_auc: 0.8021 - 2s/epoch - 3ms/step
Epoch 16/50
615/615 - 1s - loss: 0.4254 - accuracy: 0.8020 - precision: 0.7940 - recall: 0.8359 - auc: 0.8830 - val_loss: 0.5629 - val_accuracy: 0.7216 - val_precision: 0.7212 - val_recall: 0.7572 - val_auc: 0.7962 - 1s/epoch - 2ms/step
Epoch 17/50
615/615 - 1s - loss: 0.4169 - accuracy: 0.8070 - precision: 0.7977 - recall: 0.8425 - auc: 0.8878 - val_loss: 0.5771 - val_accuracy: 0.7243 - val_precision: 0.7370 - val_recall: 0.7305 - val_auc: 0.7944 - 1s/epoch - 2ms/step
Epoch 18/50
615/615 - 1s - loss: 0.4097 - accuracy: 0.8114 - precision: 0.8036 - recall: 0.8433 - auc: 0.8918 - val_loss: 0.5862 - val_accuracy: 0.7153 - val_precision: 0.7121 - val_recall: 0.7595 - val_auc: 0.7831 - 1s/epoch - 2ms/step
Epoch 19/50
615/615 - 1s - loss: 0.4031 - accuracy: 0.8116 - precision: 0.8051 - recall: 0.8411 - auc: 0.8954 - val_loss: 0.6018 - val_accuracy: 0.7229 - val_precision: 0.7283 - val_recall: 0.7452 - val_auc: 0.7919 - 1s/epoch - 2ms/step
Epoch 20/50
615/615 - 1s - loss: 0.3936 - accuracy: 0.8175 - precision: 0.8085 - recall: 0.8504 - auc: 0.9010 - val_loss: 0.5991 - val_accuracy: 0.7217 - val_precision: 0.7211 - val_recall: 0.7581 - val_auc: 0.7920 - 1s/epoch - 2ms/step
Epoch 21/50
615/615 - 1s - loss: 0.3886 - accuracy: 0.8203 - precision: 0.8132 - recall: 0.8493 - auc: 0.9037 - val_loss: 0.6165 - val_accuracy: 0.7196 - val_precision: 0.7206 - val_recall: 0.7525 - val_auc: 0.7899 - 1s/epoch - 2ms/step
Epoch 22/50
615/615 - 1s - loss: 0.3766 - accuracy: 0.8270 - precision: 0.8191 - recall: 0.8563 - auc: 0.9097 - val_loss: 0.6267 - val_accuracy: 0.7223 - val_precision: 0.7162 - val_recall: 0.7718 - val_auc: 0.7866 - 1s/epoch - 2ms/step
Epoch 23/50
615/615 - 1s - loss: 0.3698 - accuracy: 0.8311 - precision: 0.8240 - recall: 0.8585 - auc: 0.9133 - val_loss: 0.6488 - val_accuracy: 0.7177 - val_precision: 0.7021 - val_recall: 0.7941 - val_auc: 0.7847 - 1s/epoch - 2ms/step
Epoch 24/50
615/615 - 2s - loss: 0.3646 - accuracy: 0.8359 - precision: 0.8266 - recall: 0.8661 - auc: 0.9161 - val_loss: 0.6458 - val_accuracy: 0.7078 - val_precision: 0.7200 - val_recall: 0.7170 - val_auc: 0.7754 - 2s/epoch - 3ms/step
Epoch 25/50
615/615 - 2s - loss: 0.3552 - accuracy: 0.8383 - precision: 0.8314 - recall: 0.8642 - auc: 0.9203 - val_loss: 0.6571 - val_accuracy: 0.7065 - val_precision: 0.7128 - val_recall: 0.7293 - val_auc: 0.7750 - 2s/epoch - 2ms/step
Epoch 26/50
615/615 - 1s - loss: 0.3459 - accuracy: 0.8428 - precision: 0.8351 - recall: 0.8692 - auc: 0.9246 - val_loss: 0.6863 - val_accuracy: 0.7095 - val_precision: 0.7051 - val_recall: 0.7587 - val_auc: 0.7718 - 1s/epoch - 2ms/step
Epoch 27/50
615/615 - 2s - loss: 0.3363 - accuracy: 0.8496 - precision: 0.8430 - recall: 0.8733 - auc: 0.9291 - val_loss: 0.6876 - val_accuracy: 0.7016 - val_precision: 0.7002 - val_recall: 0.7452 - val_auc: 0.7625 - 2s/epoch - 3ms/step
Epoch 28/50
615/615 - 2s - loss: 0.3303 - accuracy: 0.8513 - precision: 0.8456 - recall: 0.8736 - auc: 0.9317 - val_loss: 0.7024 - val_accuracy: 0.6993 - val_precision: 0.7074 - val_recall: 0.7191 - val_auc: 0.7671 - 2s/epoch - 3ms/step
Resultados
[ ]:
plot_metrics(history)
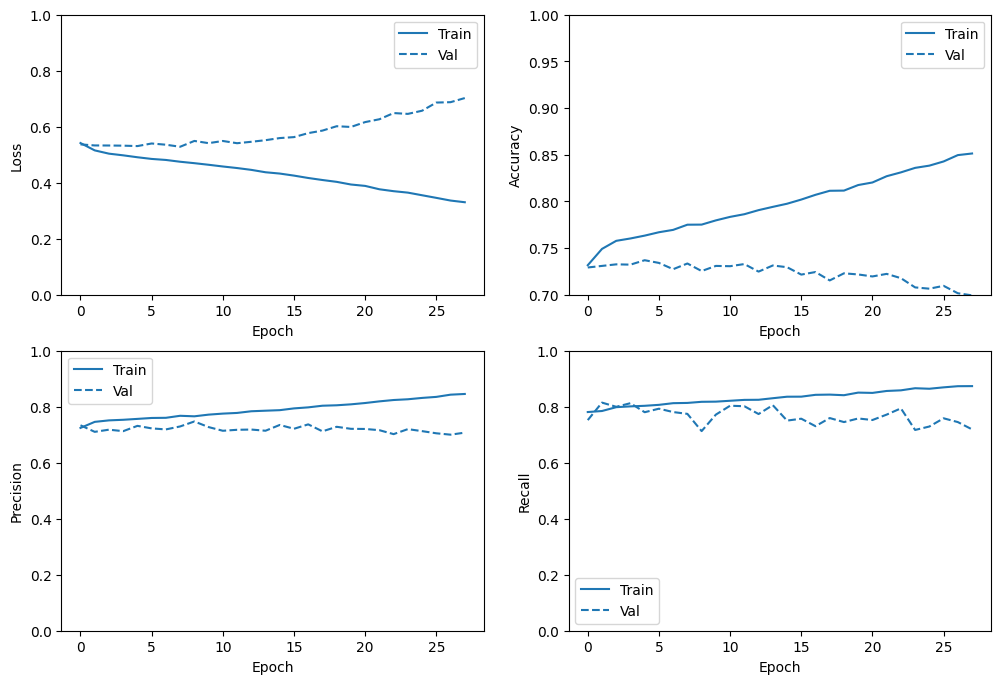
[ ]:
train_pred = rna.predict(X_train)
test_pred = rna.predict(X_test)
print('Número de exemplos positivos do conjunto de teste =', len(y_test[y_test > 0.9]))
results = rna.evaluate(X_test, y_test, verbose=0)
for name, value in zip(rna.metrics_names, results):
print(f'{name}: {value:.4f}')
615/615 [==============================] - 1s 1ms/step
205/205 [==============================] - 0s 1ms/step
Número de exemplos positivos do conjunto de teste = 3410
loss: 0.5284
accuracy: 0.7335
precision: 0.7296
recall: 0.7745
auc: 0.8097
[ ]:
precision = results[2]
recall = results[3]
F1 = 2*precision*recall/(precision + recall)
print(f'Pontuação F1 = {F1:.4f}')
Pontuação F1 = 0.7514
[ ]:
ConfusionMatrixDisplay.from_predictions(y_test, np.round(test_pred),
normalize='true', cmap='Blues',
values_format='.3f')
plt.show()
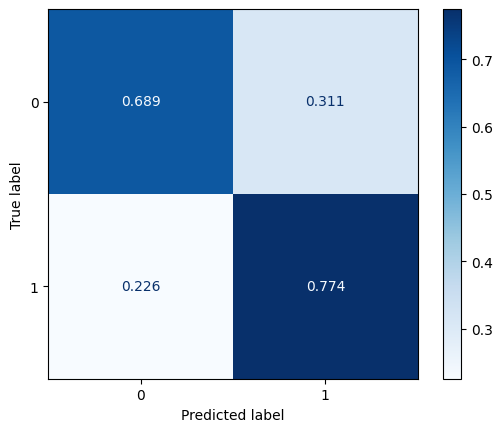
[ ]:
from sklearn.metrics import balanced_accuracy_score
balanced_accuracy_score(y_test, np.round(test_pred))
0.7317478490276376
[ ]:
fp_train, tp_train, _ = roc_curve(y_train, train_pred)
fp_test, tp_test, _ = roc_curve(y_test, test_pred)
plt.figure(figsize=(8, 6))
plt.plot(100*fp_train, 100*tp_train, 'b', label='Dados treinamento')
plt.plot(100*fp_test, 100*tp_test, 'r', label='Dados teste')
plt.xlabel('Positivos falsos [%]')
plt.ylabel('Positivos verdadeiros [%]')
plt.xlim([0,100])
plt.ylim([0,100])
plt.grid(True)
plt.legend()
plt.show()
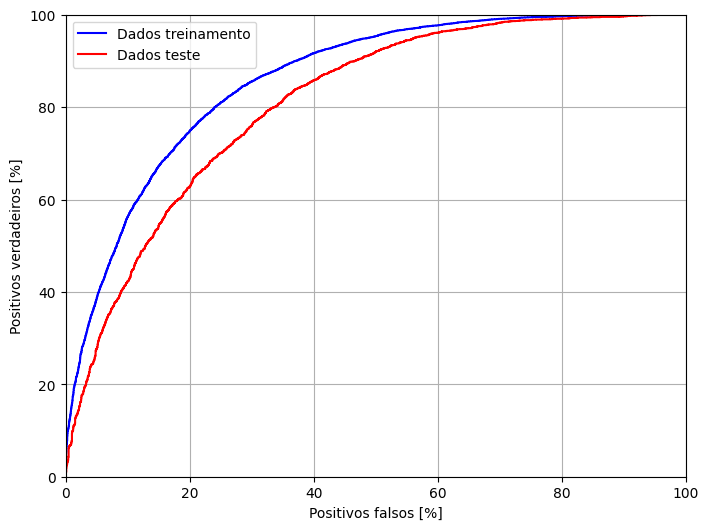
[ ]:
custo_e_metricas_train = rna.evaluate(X_train, y_train)
custo_e_metricas_test = rna.evaluate(X_test, y_test)
615/615 [==============================] - 1s 1ms/step - loss: 0.4630 - accuracy: 0.7813 - precision: 0.7748 - recall: 0.8169 - auc: 0.8603
205/205 [==============================] - 0s 1ms/step - loss: 0.5284 - accuracy: 0.7335 - precision: 0.7296 - recall: 0.7745 - auc: 0.8097