Leitura dos Dados
[ ]:
path = '/content/drive/MyDrive/Trabalho/Cancer/Datasets/colorretal.csv'
df = read_csv(path, drop_id=True)
df.head(3)
(68013, 68)
| ESCOLARI | IDADE | SEXO | UFNASC | UFRESID | IBGE | CIDADE | CATEATEND | DTCONSULT | DIAGPREV | ... | RECNENHUM | RECLOCAL | RECREGIO | RECDIST | REC01 | REC02 | REC03 | REC04 | IBGEATEN | HABILIT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 19 | 2 | SP | MG | 3100104 | ABADIA DOS DOURADOS | 2 | 2000-01-05 | 1 | ... | 1 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | 3550308 | CACON |
| 1 | 4 | 19 | 2 | SP | SP | 3539301 | PIRASSUNUNGA | 9 | 2001-06-08 | 2 | ... | 0 | 1 | 0 | 0 | NaN | NaN | NaN | NaN | 3525300 | CACON |
| 2 | 4 | 19 | 2 | SP | SP | 3550308 | SAO PAULO | 9 | 2002-02-04 | 2 | ... | 1 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | 3550308 | CACON |
3 rows × 68 columns
Análise dos dados
Nesta seção serão analisadas informações dos dados com gráficos e verificação de dados faltantes.
Informações
[ ]:
data = df.copy()
[ ]:
data.shape
(68013, 68)
[ ]:
data.head(3)
| ESCOLARI | IDADE | SEXO | UFNASC | UFRESID | IBGE | CIDADE | CATEATEND | DTCONSULT | DIAGPREV | ... | RECNENHUM | RECLOCAL | RECREGIO | RECDIST | REC01 | REC02 | REC03 | REC04 | IBGEATEN | HABILIT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 19 | 2 | SP | MG | 3100104 | ABADIA DOS DOURADOS | 2 | 2000-01-05 | 1 | ... | 1 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | 3550308 | CACON |
| 1 | 4 | 19 | 2 | SP | SP | 3539301 | PIRASSUNUNGA | 9 | 2001-06-08 | 2 | ... | 0 | 1 | 0 | 0 | NaN | NaN | NaN | NaN | 3525300 | CACON |
| 2 | 4 | 19 | 2 | SP | SP | 3550308 | SAO PAULO | 9 | 2002-02-04 | 2 | ... | 1 | 0 | 0 | 0 | NaN | NaN | NaN | NaN | 3550308 | CACON |
3 rows × 68 columns
[ ]:
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 68013 entries, 0 to 68012
Data columns (total 68 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 ESCOLARI 68013 non-null int64
1 IDADE 68013 non-null int64
2 SEXO 68013 non-null int64
3 UFNASC 68013 non-null object
4 UFRESID 68013 non-null object
5 IBGE 68013 non-null int64
6 CIDADE 68013 non-null object
7 CATEATEND 68013 non-null int64
8 DTCONSULT 68013 non-null object
9 DIAGPREV 68013 non-null int64
10 DTDIAG 68013 non-null object
11 TOPO 68013 non-null object
12 TOPOGRUP 68013 non-null object
13 DESCTOPO 68013 non-null object
14 MORFO 68013 non-null int64
15 comportamento 68013 non-null int64
16 DESCMORFO 68013 non-null object
17 EC 68013 non-null object
18 ECGRUP 68013 non-null object
19 T 68013 non-null object
20 N 68013 non-null object
21 M 68013 non-null object
22 META01 17092 non-null object
23 META02 5431 non-null object
24 META03 1513 non-null object
25 META04 379 non-null object
26 DTTRAT 68013 non-null object
27 NAOTRAT 68013 non-null int64
28 TRATAMENTO 68013 non-null object
29 TRATHOSP 68013 non-null object
30 TRATFAPOS 68013 non-null object
31 NENHUM 68013 non-null int64
32 CIRURGIA 68013 non-null int64
33 RADIO 68013 non-null int64
34 QUIMIO 68013 non-null int64
35 HORMONIO 68013 non-null int64
36 TMO 68013 non-null int64
37 IMUNO 68013 non-null int64
38 OUTROS 68013 non-null int64
39 NENHUMANT 68013 non-null int64
40 NENHUMAPOS 68013 non-null int64
41 CIRURAPOS 68013 non-null int64
42 RADIOAPOS 68013 non-null int64
43 QUIMIOAPOS 68013 non-null int64
44 HORMOAPOS 68013 non-null int64
45 TMOAPOS 68013 non-null int64
46 IMUNOAPOS 68013 non-null int64
47 OUTROAPOS 68013 non-null int64
48 DTULTINFO 68013 non-null object
49 ULTINFO 68012 non-null float64
50 CONSDIAG 68013 non-null int64
51 TRATCONS 63852 non-null float64
52 DIAGTRAT 63852 non-null float64
53 ANODIAG 68013 non-null int64
54 FAIXAETAR 68013 non-null object
55 DRS 63763 non-null object
56 RRAS 68013 non-null int64
57 DTRECIDIVA 68013 non-null object
58 RECNENHUM 68013 non-null int64
59 RECLOCAL 68013 non-null int64
60 RECREGIO 68013 non-null int64
61 RECDIST 68013 non-null int64
62 REC01 8610 non-null object
63 REC02 2479 non-null object
64 REC03 693 non-null object
65 REC04 0 non-null float64
66 IBGEATEN 68013 non-null int64
67 HABILIT 68013 non-null object
dtypes: float64(4), int64(34), object(30)
memory usage: 35.3+ MB
[ ]:
data.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| ESCOLARI | 68013.0 | 4.388896e+00 | 2.841315 | 1.0 | 2.0 | 3.0 | 9.0 | 9.0 |
| IDADE | 68013.0 | 6.180885e+01 | 13.390723 | 0.0 | 53.0 | 63.0 | 71.0 | 105.0 |
| SEXO | 68013.0 | 1.483393e+00 | 0.499728 | 1.0 | 1.0 | 1.0 | 2.0 | 2.0 |
| IBGE | 68013.0 | 3.544946e+06 | 327098.843433 | 1100015.0 | 3518404.0 | 3541000.0 | 3550308.0 | 9999999.0 |
| CATEATEND | 68013.0 | 4.324967e+00 | 3.382186 | 1.0 | 2.0 | 2.0 | 9.0 | 9.0 |
| DIAGPREV | 68013.0 | 1.554056e+00 | 0.497073 | 1.0 | 1.0 | 2.0 | 2.0 | 2.0 |
| MORFO | 68013.0 | 8.190125e+04 | 1272.052137 | 80003.0 | 81403.0 | 81403.0 | 82113.0 | 97583.0 |
| comportamento | 68013.0 | 2.984032e+00 | 0.125351 | 2.0 | 3.0 | 3.0 | 3.0 | 3.0 |
| NAOTRAT | 68013.0 | 7.816506e+00 | 0.877419 | 1.0 | 8.0 | 8.0 | 8.0 | 9.0 |
| NENHUM | 68013.0 | 6.434064e-02 | 0.245361 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| CIRURGIA | 68013.0 | 7.033361e-01 | 0.456790 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 |
| RADIO | 68013.0 | 2.431006e-01 | 0.428959 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| QUIMIO | 68013.0 | 6.194404e-01 | 0.485528 | 0.0 | 0.0 | 1.0 | 1.0 | 1.0 |
| HORMONIO | 68013.0 | 5.616573e-03 | 0.074734 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| TMO | 68013.0 | 1.176246e-04 | 0.010845 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| IMUNO | 68013.0 | 1.337980e-03 | 0.036554 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| OUTROS | 68013.0 | 5.701851e-02 | 0.231880 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| NENHUMANT | 68013.0 | 9.996030e-01 | 0.019921 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| NENHUMAPOS | 68013.0 | 9.456869e-01 | 0.226636 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| CIRURAPOS | 68013.0 | 7.307427e-03 | 0.085171 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| RADIOAPOS | 68013.0 | 2.209872e-02 | 0.147006 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| QUIMIOAPOS | 68013.0 | 1.664388e-02 | 0.127934 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| HORMOAPOS | 68013.0 | 1.029215e-04 | 0.010145 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| TMOAPOS | 68013.0 | 0.000000e+00 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| IMUNOAPOS | 68013.0 | 1.029215e-04 | 0.010145 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| OUTROAPOS | 68013.0 | 1.321806e-02 | 0.114208 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| ULTINFO | 68012.0 | 2.523584e+00 | 0.855408 | 1.0 | 2.0 | 3.0 | 3.0 | 4.0 |
| CONSDIAG | 68013.0 | 4.002275e+01 | 112.661516 | 0.0 | 6.0 | 21.0 | 43.0 | 5558.0 |
| TRATCONS | 63852.0 | 5.118128e+01 | 109.315691 | 0.0 | 8.0 | 30.0 | 63.0 | 5608.0 |
| DIAGTRAT | 63852.0 | 6.226381e+01 | 107.534186 | 0.0 | 5.0 | 42.0 | 84.0 | 4828.0 |
| ANODIAG | 68013.0 | 2.011722e+03 | 5.407356 | 2000.0 | 2008.0 | 2012.0 | 2016.0 | 2021.0 |
| RRAS | 68013.0 | 1.497524e+01 | 22.078279 | 1.0 | 6.0 | 10.0 | 13.0 | 99.0 |
| RECNENHUM | 68013.0 | 8.784203e-01 | 0.326802 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| RECLOCAL | 68013.0 | 3.614015e-02 | 0.186640 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| RECREGIO | 68013.0 | 3.317013e-02 | 0.179082 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| RECDIST | 68013.0 | 6.179701e-02 | 0.240788 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| REC04 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| IBGEATEN | 68013.0 | 3.534135e+06 | 18508.158101 | 3502804.0 | 3516200.0 | 3543402.0 | 3550308.0 | 3555000.0 |
[ ]:
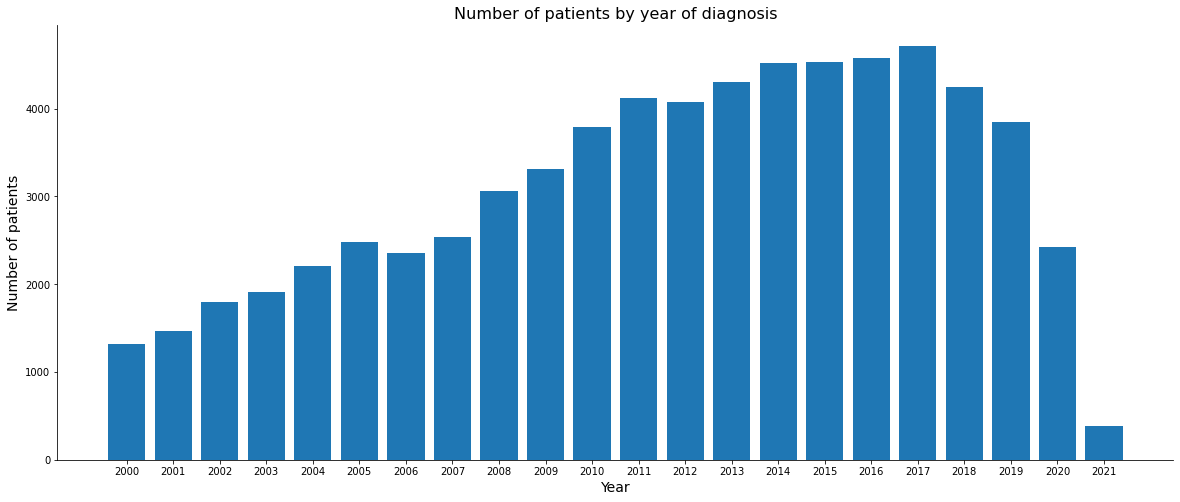
plt.figure(figsize=(20, 8))
plt.bar(height = data.ANODIAG.value_counts().sort_index(), x=np.sort(data.ANODIAG.unique()))
plt.xlabel('Year', size=14)
plt.xticks(np.sort(data.ANODIAG.unique()))
plt.ylabel('Number of patients', size=14)
plt.title('Number of patients by year of diagnosis', size=16)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.show()
[ ]:
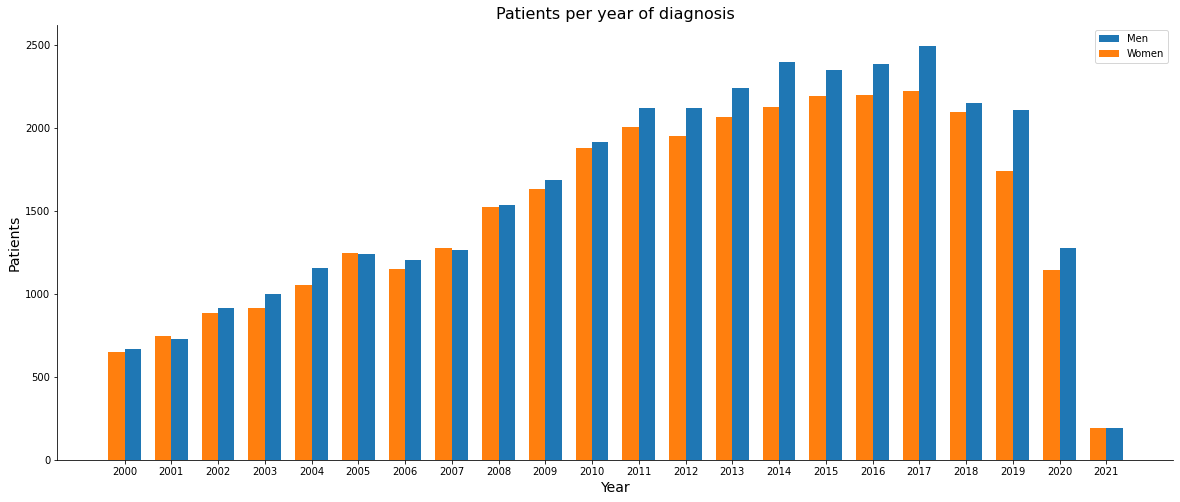
masc = data[data.SEXO == 1]
fem = data[data.SEXO == 2]
mascx = np.sort(masc.ANODIAG.unique())
mascy = masc.ANODIAG.value_counts().sort_index()
femx = np.sort(fem.ANODIAG.unique())
femy = fem.ANODIAG.value_counts().sort_index()
[ ]:
fig, ax = plt.subplots(figsize=(20, 8))
width = 0.35
ax1 = ax.bar(mascx + width/2, mascy, width, label='Men')
ax2 = ax.bar(femx - width/2, femy, width, label='Women')
ax.set_xlabel('Year', size=14)
ax.set_xticks(mascx)
ax.set_ylabel('Patients', size=14)
ax.set_title('Patients per year of diagnosis', size=16)
ax.legend()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.show()
[ ]:
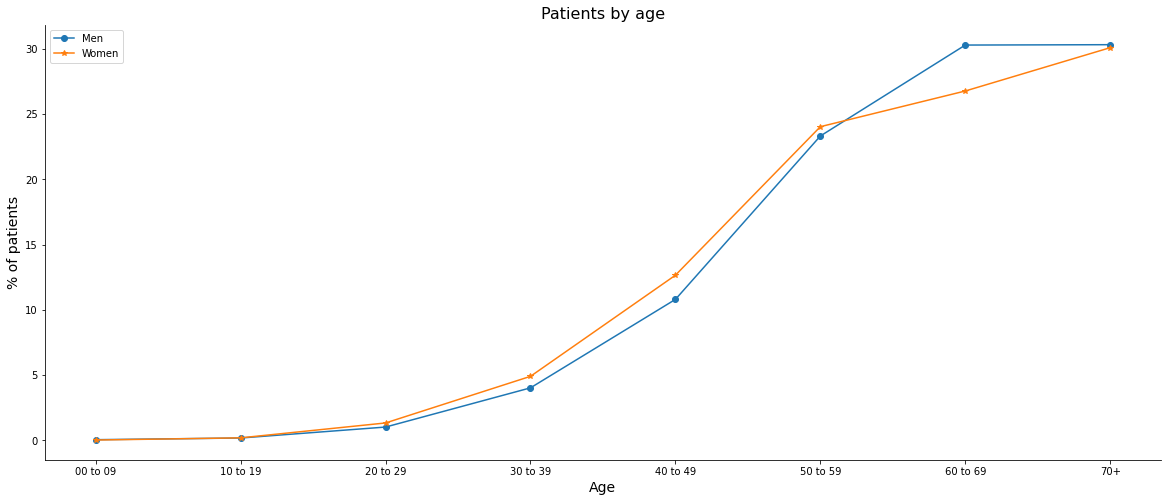
# Replacing the string format for the age group column
before = ['00-09', '10-19', '20-29', '30-39', '40-49', '50-59', '60-69']
after = ['00 to 09', '10 to 19', '20 to 29', '30 to 39', '40 to 49', '50 to 59', '60 to 69']
masc.FAIXAETAR.replace(before, after, inplace=True)
fem.FAIXAETAR.replace(before, after, inplace=True)
mascx = np.sort(masc.FAIXAETAR.unique())
mascy = masc.FAIXAETAR.value_counts().sort_index()
femx = np.sort(fem.FAIXAETAR.unique())
femy = fem.FAIXAETAR.value_counts().sort_index()
[ ]:
fig, ax = plt.subplots(figsize=(20, 8))
ax1 = ax.plot(mascx, (mascy/masc.shape[0])*100, label='Men', marker='o')
ax2 = ax.plot(femx, (femy/fem.shape[0])*100, label='Women', marker='*')
ax.set_xlabel('Age', size=14)
ax.set_ylabel('% of patients', size=14)
ax.set_title('Patients by age', size=16)
ax.legend()
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.show()
[ ]:
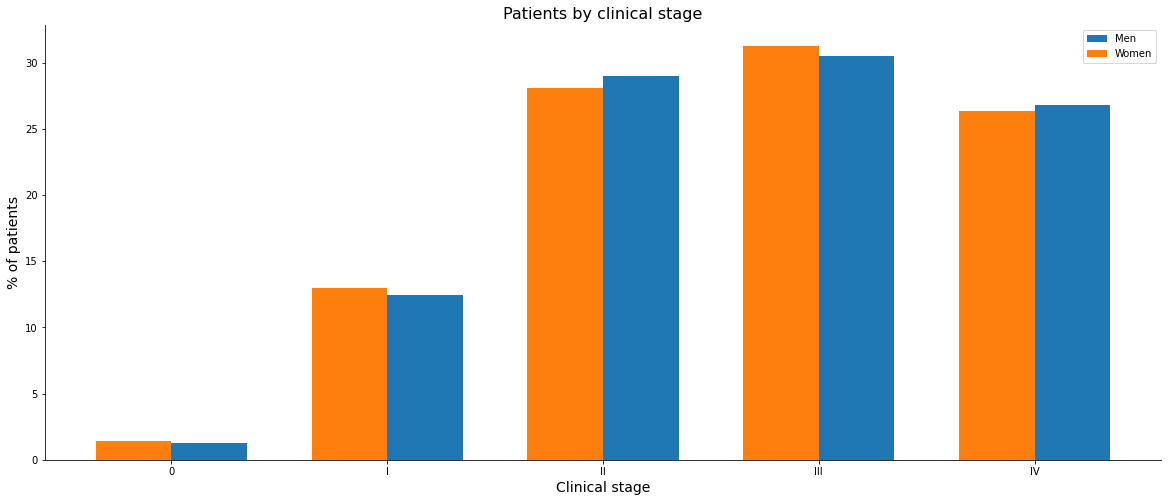
EC = list(np.sort(data.ECGRUP.unique()))[:5] # Categories 0, I, II, III, IV, without X and Y
mascEC = masc.loc[masc.ECGRUP.isin(EC)]
femEC = fem.loc[fem.ECGRUP.isin(EC)]
mascx = np.sort(mascEC.ECGRUP.unique())
mascy = mascEC.ECGRUP.value_counts().sort_index()
femx = np.sort(femEC.ECGRUP.unique())
femy = femEC.ECGRUP.value_counts().sort_index()
[ ]:
x = np.arange(len(mascx))
fig, ax = plt.subplots(figsize=(20, 8))
width = 0.35
ax1 = ax.bar(x + width/2, (mascy/mascEC.shape[0])*100, width, label='Men')
ax2 = ax.bar(x - width/2, (femy/femEC.shape[0])*100, width, label='Women')
ax.set_xlabel('Clinical stage', size=14)
ax.set_ylabel('% of patients', size=14)
ax.set_title('Patients by clinical stage', size=16)
ax.legend()
ax.set_xticks(x)
ax.set_xticklabels(list(mascx))
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.show()
[ ]:
df_diag1 = data[data.DIAGPREV == 1] # without diagnosis/without treatment
df_diag2 = data[data.DIAGPREV == 2] # with diagnosis/without treatment
x = np.sort(df_diag1.ANODIAG.unique())
y = df_diag1.groupby('ANODIAG')['CONSDIAG'].median()
[ ]:
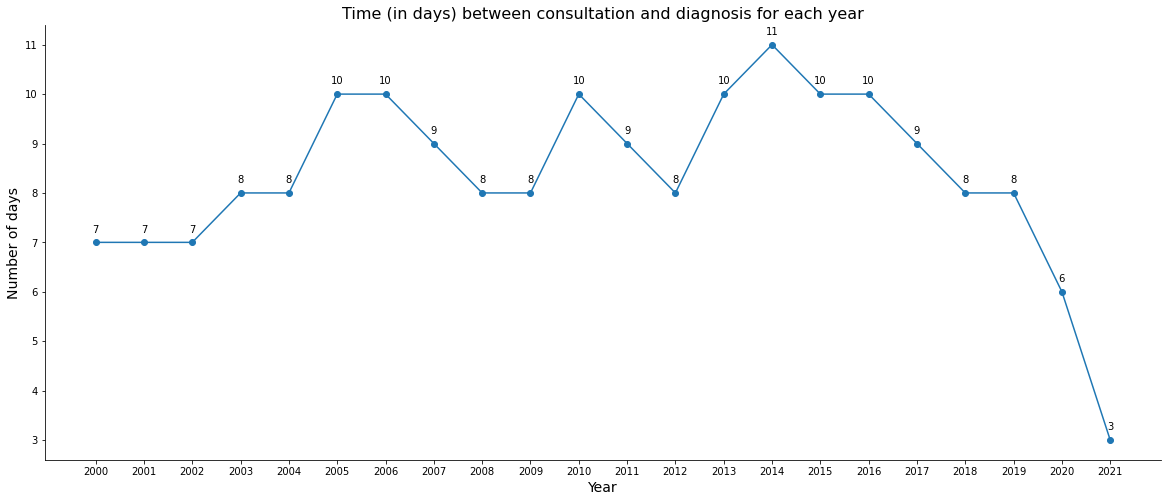
plt.figure(figsize=(20, 8))
plt.plot(x, y, marker='o')
plt.xlabel('Year', size=14)
plt.xticks(x)
plt.ylabel('Number of days', size=14)
plt.title('Time (in days) between consultation and diagnosis for each year', size=16)
for xi, yi in zip(x,y):
label = '{:.0f}'.format(yi)
plt.annotate(label, # this is the text
(xi, yi), # this is the point to label
textcoords='offset points', # how to position the text
xytext=(0, 10), # distance from text to points (x,y)
ha='center') # horizontal alignment can be left, right or center
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.show()
[ ]:
# 1 – Alive with cancer; 2 – Alive, without other specifications;
# 3 – Death by cancer; 4 – Death by other causes, without other specifications
data['ULTINFO'].value_counts()
3.0 27923
2.0 23689
1.0 8371
4.0 8029
Name: ULTINFO, dtype: int64
[ ]:
mascx = np.sort(masc.ULTINFO.unique())
mascy = masc.ULTINFO.value_counts().sort_index()
femx = np.sort(fem.ULTINFO.unique())
femy = fem.ULTINFO.value_counts().sort_index()
x_ticks = ['Alive with cancer', 'Alive, without other specifications', 'Death by cancer', 'Death by other causes']
[ ]:
x = np.arange(len(x_ticks))
fig, ax = plt.subplots(figsize=(20, 8))
width = 0.35
ax1 = ax.bar(x + width/2, mascy, width, label='Men')
ax2 = ax.bar(x - width/2, femy, width, label='Women')
ax.set_xlabel('Last information', size=14)
ax.set_ylabel('Number of pacients', size=14)
ax.set_title('Number of patients by last information category', size=16)
ax.legend()
ax.set_xticks(x)
ax.set_xticklabels(list(x_ticks))
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
plt.show()
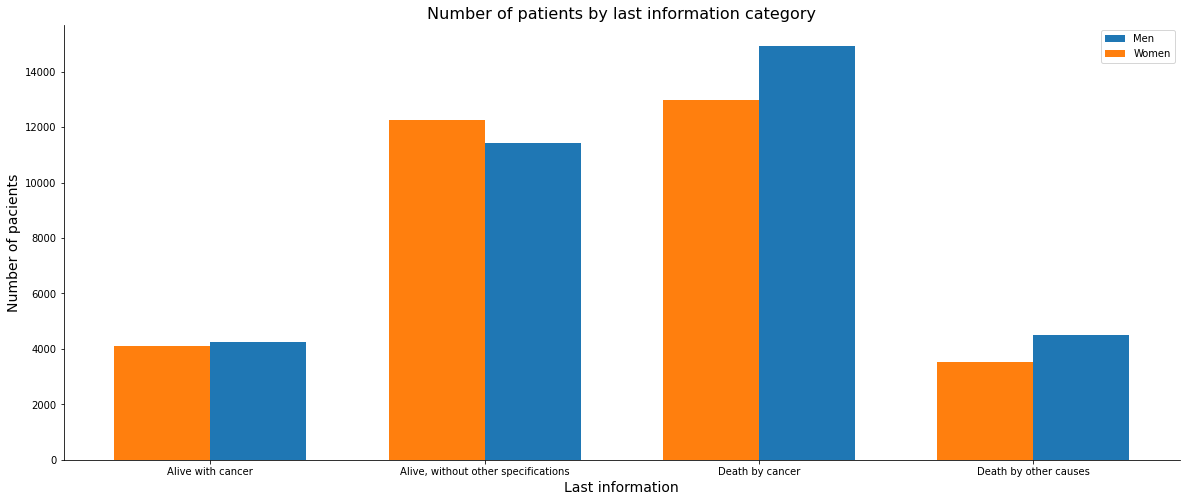
[ ]:
df_aux = data.copy()
df_aux.drop(columns=[#'S',
'META03','META04',
#'QUIMIOANT','HORMOANT','TMOANT','IMUNOANT','OUTROANT',
#'CICI','CICIGRUP','CICISUBGRU',
'REC04','TMOAPOS'], inplace=True)
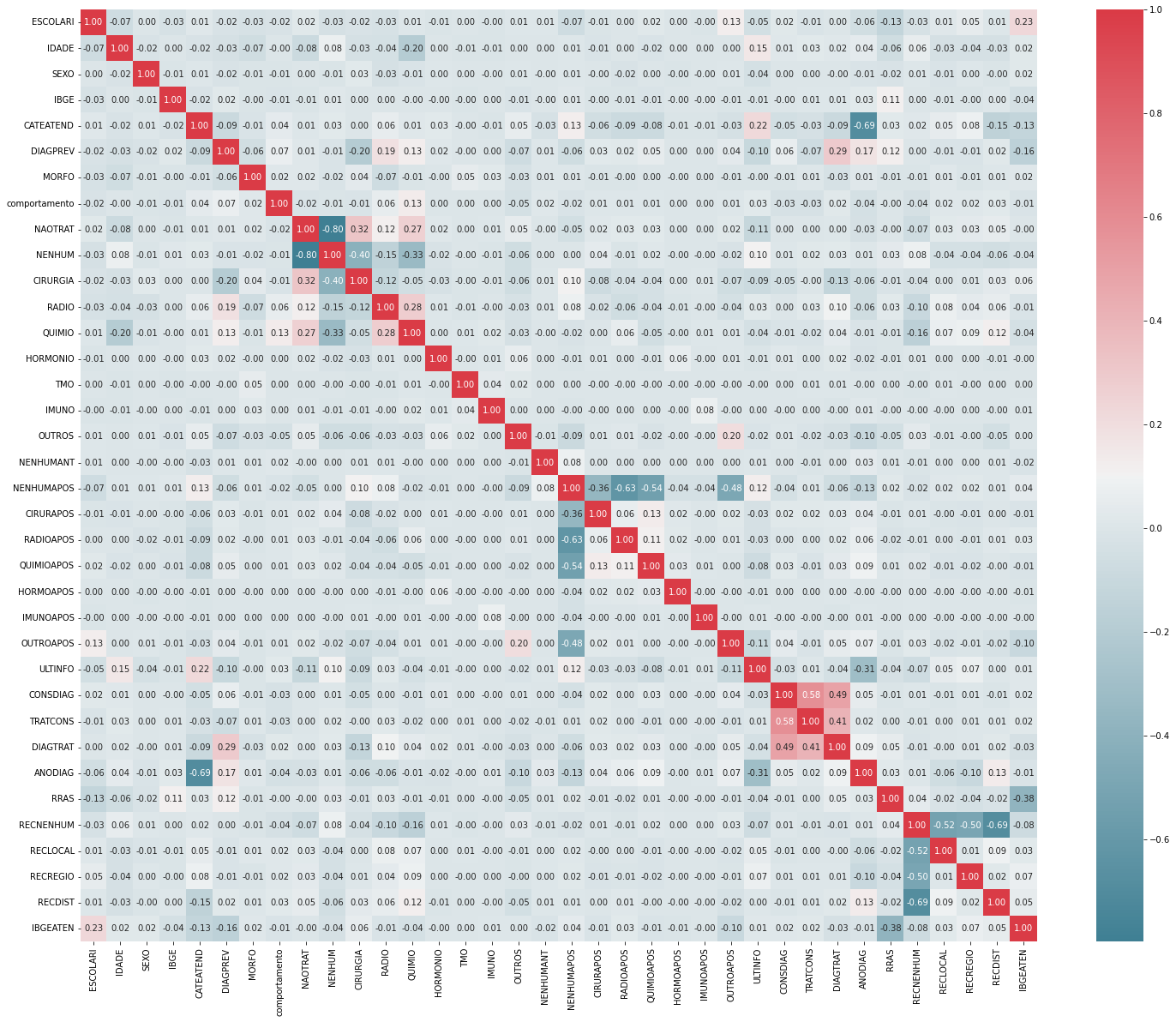
corr_matrix = df_aux.corr()
abs(corr_matrix['ULTINFO']).sort_values(ascending = False)
ULTINFO 1.000000
ANODIAG 0.307997
CATEATEND 0.222954
IDADE 0.152825
NENHUMAPOS 0.123002
NAOTRAT 0.114400
OUTROAPOS 0.106963
NENHUM 0.104858
DIAGPREV 0.102796
CIRURGIA 0.085427
QUIMIOAPOS 0.079463
RECREGIO 0.074847
RECNENHUM 0.067192
RECLOCAL 0.052129
ESCOLARI 0.047074
SEXO 0.043748
QUIMIO 0.043335
DIAGTRAT 0.041150
RRAS 0.035150
RADIOAPOS 0.034604
CONSDIAG 0.034106
CIRURAPOS 0.032537
comportamento 0.031074
RADIO 0.027211
OUTROS 0.015453
IBGEATEN 0.014499
HORMONIO 0.009892
HORMOAPOS 0.007904
NENHUMANT 0.007884
TRATCONS 0.007383
IMUNOAPOS 0.007345
IBGE 0.006388
MORFO 0.004807
RECDIST 0.003953
TMO 0.001884
IMUNO 0.000166
Name: ULTINFO, dtype: float64
[ ]:
fig, ax = plt.subplots(figsize = (25, 20))
colormap = sns.diverging_palette(220, 10, as_cmap = True)
sns.heatmap(corr_matrix, cmap = colormap, annot = True, fmt = '.2f')
fig.show()
[ ]:
data.iloc[:,:38].hist(bins=10, figsize=(20, 15))
plt.show()
[ ]:
data.iloc[:,38:58].hist(bins=10, figsize=(20, 15))
plt.show()
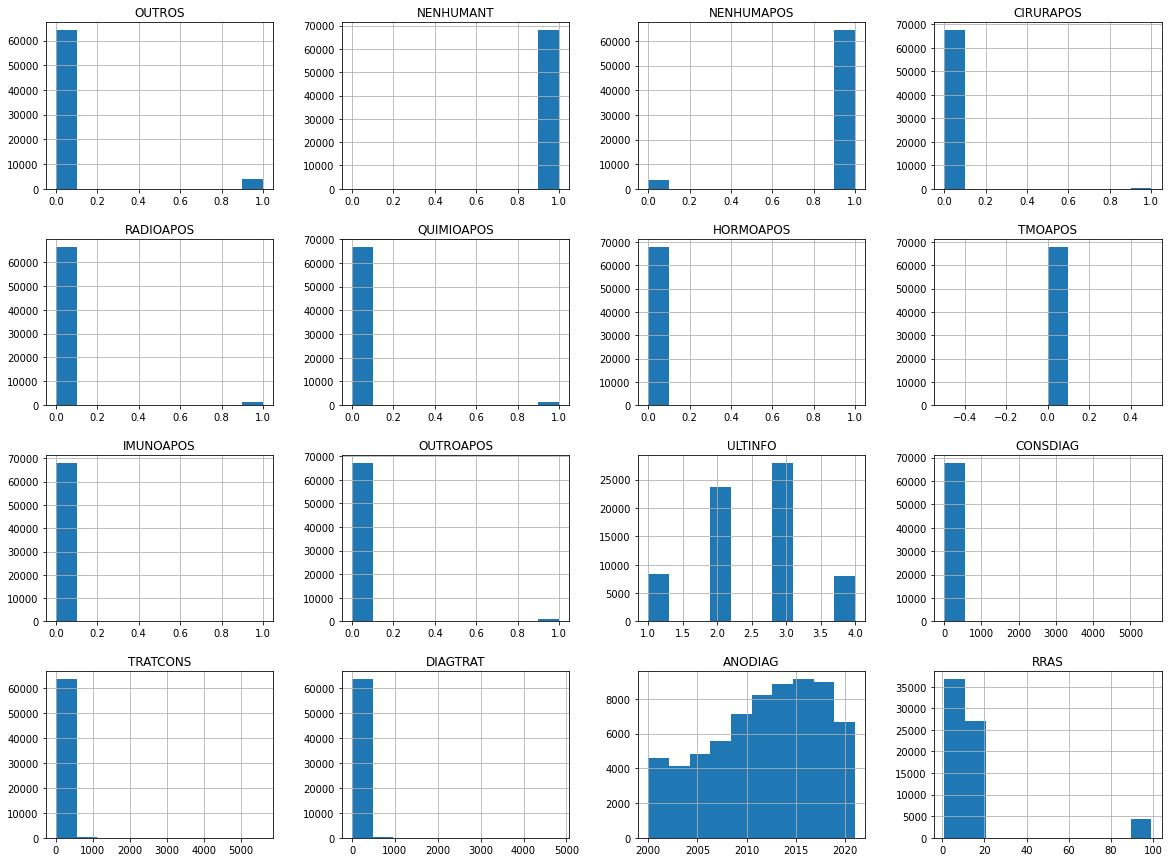
[ ]:
data.iloc[:, 58:].hist(bins=10, figsize=(20, 15))
plt.show()
Valores faltantes
[ ]:
missing = data.isna().sum().sort_values(ascending=False)
prop = missing[missing > 0]/data.shape[0]
prop
REC04 1.000000
META04 0.994428
REC03 0.989811
META03 0.977754
REC02 0.963551
META02 0.920148
REC01 0.873407
META01 0.748695
DRS 0.062488
TRATCONS 0.061179
DIAGTRAT 0.061179
ULTINFO 0.000015
dtype: float64
[ ]:
plt.figure(figsize=(12, 5))
plt.bar(height = prop*100, x=prop.index)
plt.xlabel('Variable', size=14)
plt.ylabel('%', size=14)
plt.title('Percentage of missing data per column', size=16)
plt.xticks(rotation=30)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['right'].set_visible(False)
plt.show()
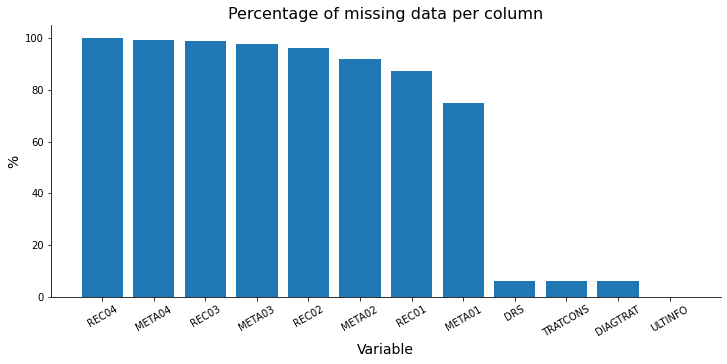
[ ]:
# REC04 - Local da recidiva/metástase. Formato: C99
data[data['REC04'].isna() == False]['REC04'].shape
(0,)
[ ]:
# META04 - Metástase. Formato: C99
data[data['META04'].isna() == False]['META04'].shape
(379,)
[ ]:
# REC03 - Local da recidiva/metástase. Formato: C99
data[data['REC03'].isna() == False]['REC03'].shape
(693,)
[ ]:
# META03 - Metástase. Formato: C99
data[data['META03'].isna() == False]['META03'].shape
(1513,)
[ ]:
# REC02 - Local da recidiva/metástase. Formato: C99
data[data['REC02'].isna() == False]['REC02'].shape
(2479,)
[ ]:
# META02 - Metástase. Formato: C99
data[data['META02'].isna() == False]['META02'].shape
(5431,)
[ ]:
# REC01 - Local da recidiva/metástase. Formato: C99
data[data['REC01'].isna() == False]['REC01'].shape
(8610,)
[ ]:
# META01 - Metástase. Formato: C99
data[data['META01'].isna() == False]['META01'].shape
(17092,)
[ ]:
# DRS - DRS
data[data['DRS'].isna() == False]['DRS'].shape
(63763,)
[ ]:
# TRATCONS - Diferença em dias entre as datas de consulta e tratamento
data[data['TRATCONS'].isna() == False]['TRATCONS'].shape
(63852,)
[ ]:
# DIAGTRAT - Diferença em dias entre as datas de tratamento e diagnóstico
data[data['DIAGTRAT'].isna() == False]['DIAGTRAT'].shape
(63852,)
[ ]:
# ULTINFO - Última informação do paciente
data[data['ULTINFO'].isna() == False]['ULTINFO'].shape
(68012,)
Análise das colunas
Nesta seção, as colunas serão analisadas individualmente, após isso, uma função será criada para realizar a limpeza e seleção dos dados.
As colunas foram divididas de acordo com seus tipos.
Como mostrado na imagem na página inicial, foram feitas algumas seleções nas de grupo de estadiamento clínico, morfologia e comportamento, além da retirada de várias colunas que não serão utilizadas.
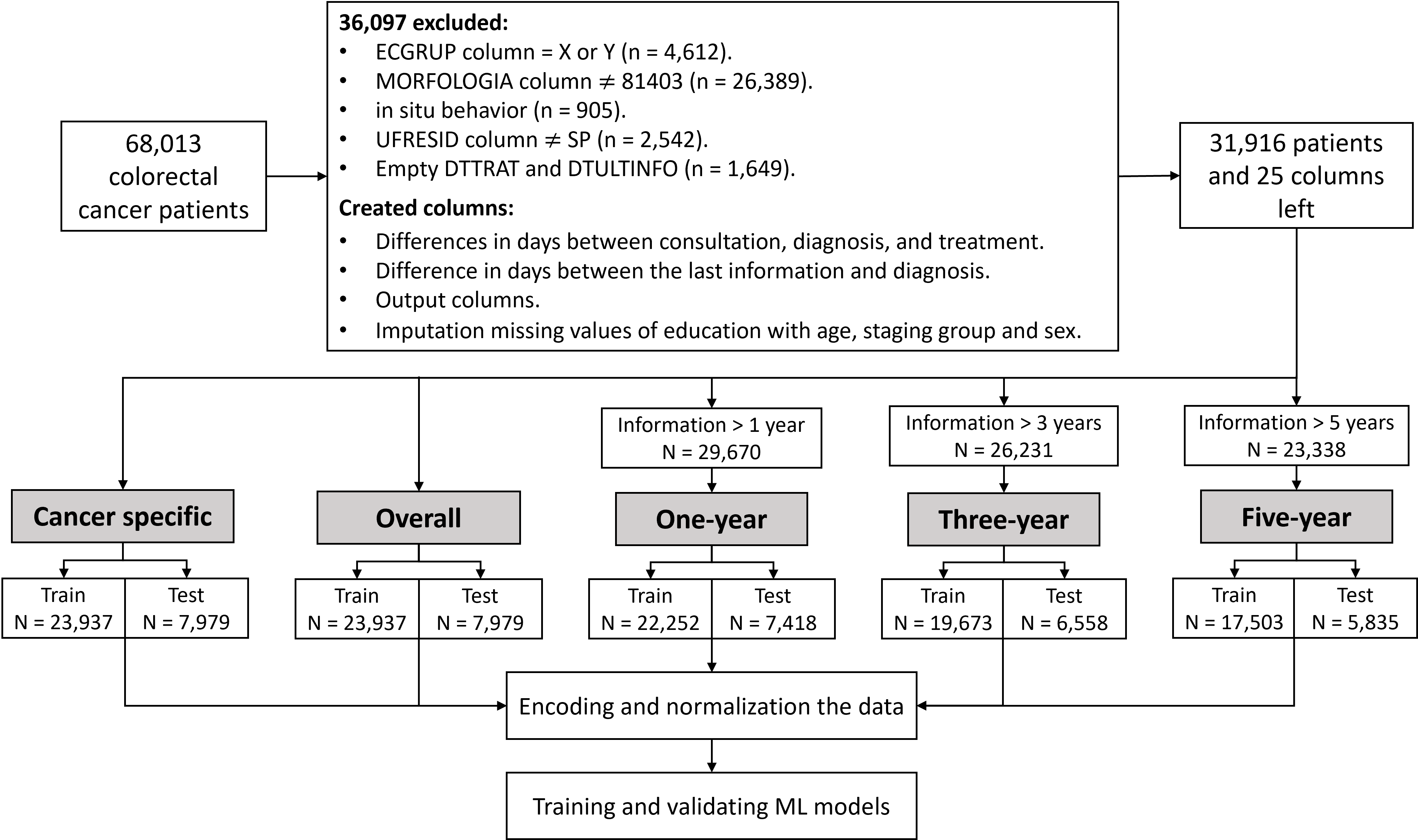{kind=link}
Verifique a seção das funções para ver a função completa.
[ ]:
df_aux = read_csv(path, drop_id=True)
(68013, 68)
[ ]:
df_aux.columns
Index(['ESCOLARI', 'IDADE', 'SEXO', 'UFNASC', 'UFRESID', 'IBGE', 'CIDADE',
'CATEATEND', 'DTCONSULT', 'DIAGPREV', 'DTDIAG', 'TOPO', 'TOPOGRUP',
'DESCTOPO', 'MORFO', 'comportamento', 'DESCMORFO', 'EC', 'ECGRUP', 'T',
'N', 'M', 'META01', 'META02', 'META03', 'META04', 'DTTRAT', 'NAOTRAT',
'TRATAMENTO', 'TRATHOSP', 'TRATFAPOS', 'NENHUM', 'CIRURGIA', 'RADIO',
'QUIMIO', 'HORMONIO', 'TMO', 'IMUNO', 'OUTROS', 'NENHUMANT',
'NENHUMAPOS', 'CIRURAPOS', 'RADIOAPOS', 'QUIMIOAPOS', 'HORMOAPOS',
'TMOAPOS', 'IMUNOAPOS', 'OUTROAPOS', 'DTULTINFO', 'ULTINFO', 'CONSDIAG',
'TRATCONS', 'DIAGTRAT', 'ANODIAG', 'FAIXAETAR', 'DRS', 'RRAS',
'DTRECIDIVA', 'RECNENHUM', 'RECLOCAL', 'RECREGIO', 'RECDIST', 'REC01',
'REC02', 'REC03', 'REC04', 'IBGEATEN', 'HABILIT'],
dtype='object')
Datas
[ ]:
# #NULL! to NaN
df_aux.loc[df_aux.DTRECIDIVA == '#NULL!', 'DTRECIDIVA'] = np.nan
df_aux.loc[df_aux.DTULTINFO == '#NULL!', 'DTULTINFO'] = np.nan
df_aux.loc[df_aux.DTTRAT == '#NULL!', 'DTTRAT'] = np.nan
DTCONSULT: Data da 1ª consulta (date = 10). Formato: DD/MM/YYYY
DTDIAG: Data do diagnóstico (date = 10). Formato: DD/MM/YYYY
DTTRAT: Data de inicio do tratamento (date = 10). Formato: DD/MM/YYYY
DTULTINFO: Data da última informação do paciente (date = 10). Formato: DD/MM/YYYY
DTRECIDIVA: Data da última ocorrência de recidiva (date = 10). Formato: DD/MM/YYYY
[ ]:
# Data - DTCONSULT, DTDIAG, DTTRAT, DTULTINFO, DTRECIDIVA
dates = ['DTCONSULT', 'DTDIAG', 'DTTRAT', 'DTULTINFO', 'DTRECIDIVA']
df_aux[dates].isna().sum()
DTCONSULT 0
DTDIAG 0
DTTRAT 4161
DTULTINFO 5
DTRECIDIVA 57470
dtype: int64
[ ]:
(df_aux[dates].isna().sum()/df_aux.shape[0])*100
DTCONSULT 0.000000
DTDIAG 0.000000
DTTRAT 6.117948
DTULTINFO 0.007352
DTRECIDIVA 84.498552
dtype: float64
[ ]:
df_aux[dates].head(3)
| DTCONSULT | DTDIAG | DTTRAT | DTULTINFO | DTRECIDIVA | |
|---|---|---|---|---|---|
| 0 | 2000-01-05 | 2000-01-13 | 2000-01-13 00:00:00 | 2006-12-13 00:00:00 | NaN |
| 1 | 2001-06-08 | 2001-06-08 | 2001-07-30 00:00:00 | 2005-01-26 00:00:00 | 2004-10-26 00:00:00 |
| 2 | 2002-02-04 | 2002-02-04 | 2002-04-26 00:00:00 | 2003-06-08 00:00:00 | NaN |
Categorias numéricas
SEXO: Sexo do paciente (int = 1).
1 – MASCULINO
2 – FEMININO
[ ]:
df_aux.SEXO.value_counts()
1 35136
2 32877
Name: SEXO, dtype: int64
ESCOLARI: Código para escolaridade do paciente (int = 1).
1 – ANALFABETO
2 – ENS. FUND. INCOMPLETO
3 – ENS. FUND. COMPLETO
4 – ENSINO MÉDIO
5 – SUPERIOR
9 – IGNORADA
[ ]:
df_aux.ESCOLARI.value_counts()
2 21117
9 17133
3 11862
4 9748
5 4835
1 3318
Name: ESCOLARI, dtype: int64
CATEATEND: Categoria de atendimento ao diagnóstico (int = 1).
1 - CONVENIO
2 - SUS
3 – PARTICULAR
9 – SEM INFORMAÇÃO
[ ]:
df_aux.CATEATEND.value_counts()
2 39473
9 23273
1 5025
3 242
Name: CATEATEND, dtype: int64
DIAGPREV: Diagnóstico e tratamento anterior (int = 1).
1 – SEM DIAGNÓSTICO / SEM TRATAMENTO
2 – COM DIAGNÓSTICO / SEM TRATAMENTO
[ ]:
df_aux.DIAGPREV.value_counts()
2 37683
1 30330
Name: DIAGPREV, dtype: int64
NAOTRAT: Código da razão para não realização do tratamento (int = 1).
1 – RECUSA DO TRATAMENTO
2 – DOENÇA AVANÇADA, FALTA DE CONDIÇÕES CLINICAS
3 – OUTRAS DOENÇAS ASSOCIADAS
4 – ABANDONO DE TRATAMENTO
5 – OBITO POR CANCER
6 – OBITO POR OUTRAS CAUSAS, SOE
7 – OUTRAS
8 – NÃO SE APLICA (CASO TENHA TRATAMENTO)
9 – SEM INFORMAÇÃO
[ ]:
df_aux.NAOTRAT.value_counts()
8 63839
5 1830
7 879
2 749
9 289
6 128
3 121
1 111
4 67
Name: NAOTRAT, dtype: int64
NENHUM: Tratamento recebido no hospital = nenhum (int = 1). 0 – NÃO; 1 – SIM
CIRURGIA: Tratamento recebido no hospital = cirurgia (int = 1). 0 – NÃO; 1 – SIM
RADIO: Tratamento recebido no hospital = radioterapia (int = 1). 0 – NÃO; 1 – SIM
QUIMIO: Tratamento recebido no hospital = quimioterapia (int = 1). 0 – NÃO; 1 – SIM
HORMONIO: Tratamento recebido no hospital = hormonioterapia (int = 1). 0 – NÃO; 1 – SIM
TMO: Tratamento recebido no hospital = tmo (int = 1). 0 – NÃO; 1 – SIM
IMUNO: Tratamento recebido no hospital = imunoterapia (int = 1). 0 – NÃO; 1 – SIM
OUTROS: Tratamento recebido no hospital = outros (int = 1). 0 – NÃO; 1 – SIM
[ ]:
df_aux.NENHUM.unique()
array([0, 1])
[ ]:
df_aux.CIRURGIA.unique()
array([1, 0])
[ ]:
df_aux.RADIO.unique()
array([1, 0])
[ ]:
df_aux.QUIMIO.unique()
array([1, 0])
[ ]:
df_aux.HORMONIO.unique()
array([0, 1])
[ ]:
df_aux.TMO.unique()
array([0, 1])
[ ]:
df_aux.IMUNO.unique()
array([0, 1])
[ ]:
df_aux.OUTROS.unique()
array([1, 0])
NENHUMANT: Tratamento recebido fora do hospital e antes da admissão = nenhum (int = 1). 0 – NÃO; 1 – SIM
[ ]:
df_aux.NENHUMANT.unique()
array([1, 0])
NENHUMAPOS: Tratamento recebido fora do hospital e durante/após admissão = nenhum (int = 1). 0 – NÃO; 1 – SIM
CIRURAPOS: Tratamento recebido fora do hospital e durante/após admissão = cirurgia (int = 1). 0 – NÃO; 1 – SIM
RADIOAPOS: Tratamento recebido fora do hospital e durante/após admissão = radioterapia (int = 1). 0 – NÃO; 1 – SIM
QUIMIOAPOS: Tratamento recebido fora do hospital e durante/após admissão = quimioterapia (int = 1). 0 – NÃO; 1 – SIM
HORMOAPOS: Tratamento recebido fora do hospital e durante/após admissão = hormonioterapia (int = 1). 0 – NÃO; 1 – SIM
TMOAPOS: Tratamento recebido fora do hospital e durante/após admissão = tmo (int = 1). 0 – NÃO; 1 – SIM
IMUNOAPOS: Tratamento recebido fora do hospital e durante/após admissão = imunoterapia (int = 1). 0 – NÃO; 1 – SIM
OUTROAPOS: Tratamento recebido fora do hospital e durante/após admissão = outros (int = 1). 0 – NÃO; 1 – SIM
[ ]:
df_aux.NENHUMAPOS.unique()
array([1, 0])
[ ]:
df_aux.CIRURAPOS.unique()
array([0, 1])
[ ]:
df_aux.RADIOAPOS.unique()
array([0, 1])
[ ]:
df_aux.QUIMIOAPOS.unique()
array([0, 1])
[ ]:
df_aux.HORMOAPOS.unique()
array([0, 1])
[ ]:
df_aux.TMOAPOS.unique() ### drop
array([0])
[ ]:
df_aux.IMUNOAPOS.unique()
array([0, 1])
[ ]:
df_aux.OUTROAPOS.unique()
array([0, 1])
ULTINFO: Última informação sobre o paciente (int = 1).
1 – VIVO, COM CÂNCER
2 – VIVO, SOE
3 – OBITO POR CANCER
4 – OBITO POR OUTRAS CAUSAS, SOE
[ ]:
df_aux.ULTINFO.value_counts()
3.0 27923
2.0 23689
1.0 8371
4.0 8029
Name: ULTINFO, dtype: int64
RECNENHUM: Sem recidiva (int = 1). 0 - Não; 1 - Sim
RECLOCAL: Recidiva local (int = 1). 0 - Não; 1 - Sim
RECREGIO: Recidiva regional (int = 1). 0 - Não; 1 - Sim
RECDIST: Recidiva a distância / metástase (int = 1). 0 - Não; 1 - Sim
[ ]:
df_aux.RECNENHUM.value_counts()
1 59744
0 8269
Name: RECNENHUM, dtype: int64
[ ]:
df_aux.RECLOCAL.value_counts()
0 65555
1 2458
Name: RECLOCAL, dtype: int64
[ ]:
df_aux.RECREGIO.value_counts()
0 65757
1 2256
Name: RECREGIO, dtype: int64
[ ]:
df_aux.RECDIST.value_counts()
0 63810
1 4203
Name: RECDIST, dtype: int64
Categorias com letras
TRATAMENTO: Código de combinação dos tratamentos realizados (char = 1).
A – Cirurgia
B – Radioterapia
C – Quimioterapia
D – Cirurgia + Radioterapia
E – Cirurgia + Quimioterapia
F – Radioterapia + Quimioterapia
G – Cirurgia + Radio + Quimio
H – Cirurgia + Radio + Quimio + Hormonio
I – Outras combinações de tratamento
J – Nenhum tratamento realizadoTRATHOSP: Código de combinação dos tratamentos realizados no hospital (char = 1).
A – Cirurgia
B – Radioterapia
C – Quimioterapia
D – Cirurgia + Radioterapia
E – Cirurgia + Quimioterapia
F – Radioterapia + Quimioterapia
G – Cirurgia + Radio + Quimio
H – Cirurgia + Radio + Quimio + Hormonio
I – Outras combinações de tratamento
J – Nenhum tratamento realizado
TRATFAPOS: Código de combinação dos tratamentos realizados após admissão fora do hospital (char = 1).
A – Cirurgia
B – Radioterapia
C – Quimioterapia
D – Cirurgia + Radioterapia
E – Cirurgia + Quimioterapia
F – Radioterapia + Quimioterapia
G – Cirurgia + Radio + Quimio
H – Cirurgia + Radio + Quimio + Hormonio
I – Outras combinações de tratamento
J – Nenhum tratamento realizado
K – Sem informação
[ ]:
np.sort(df_aux.TRATAMENTO.unique())
array(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype=object)
[ ]:
np.sort(df_aux.TRATHOSP.unique())
array(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J'], dtype=object)
[ ]:
np.sort(df_aux.TRATFAPOS.unique())
array(['A', 'B', 'C', 'D', 'E', 'F', 'G', 'I', 'J'], dtype=object)
Numéricas
IDADE: Idade do paciente (int = 3).
[ ]:
df_aux.IDADE.nunique()
103
CONSDIAG: Diferença em dias entre as datas de consulta o diagnóstico (num = dias).
TRATCONS: Diferença em dias entre as datas de consulta e tratamento (num = dias).
DIAGTRAT: Diferença em dias entre as datas de tratamento e diagnóstico (num = dias).
[ ]:
df_aux.CONSDIAG.isna().sum()
0
[ ]:
df_aux.TRATCONS.isna().sum()
4161
[ ]:
df_aux.DIAGTRAT.isna().sum()
4161
ANODIAG: Ano de diagnóstico (int = 4). Formato: 9999
[ ]:
np.sort(df_aux.ANODIAG.unique())
array([2000, 2001, 2002, 2003, 2004, 2005, 2006, 2007, 2008, 2009, 2010,
2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021])
IBGE: Código da cidade de residência do paciente segundo IBGE com digito verificador (int = 7).
[ ]:
df_aux.IBGE.nunique()
1361
IBGEATEN
[ ]:
df_aux.IBGEATEN.isna().sum()
0
MORFO: Código da morfologia (char = 5). Formato: 99999
[ ]:
df_aux.MORFO.unique()
array([81403, 82113, 84803, 80103, 84813, 82493, 80323, 82403, 84903,
82632, 82633, 82102, 81402, 82463, 85603, 81473, 82203, 82443,
82453, 82433, 90703, 89003, 88103, 96873, 95913, 95903, 96553,
96803, 96903, 96503, 80003, 82623, 80203, 80102, 82553, 82103,
82603, 84303, 80703, 81482, 80413, 83103, 97023, 82612, 82613,
85743, 89363, 85103, 88903, 80043, 91203, 82153, 96843, 80133,
88003, 81233, 84403, 82303, 80833, 96733, 97283, 82213, 85503,
82013, 83233, 88503, 81903, 81243, 87203, 85723, 81433, 82513,
97143, 84703, 81203, 85763, 80213, 96983, 80763, 96993, 80702,
96703, 88043, 89333, 89803, 80503, 85703, 88583, 88513, 84603,
88013, 88023, 84413, 80123, 81413, 80513, 80523, 95713, 82413,
95953, 80843, 84823, 80023, 80333, 80723, 96833, 81303, 95963,
97583, 82313, 80713, 88303, 80303, 96753, 88533, 80733, 96523,
89013, 80113, 87463, 88053, 84713, 91403, 80153, 89353, 88523,
88913, 80753, 89343, 84723, 83133, 85713, 81223, 93643, 82903,
88063, 89203])
RRAS: RRAS (int = 200). [1,2,3, … ,16,17,99]
[ ]:
np.sort(df_aux.RRAS.unique())
array([ 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17,
99])
[ ]:
df_aux.RRAS.value_counts()
6 17026
13 7279
12 6948
9 4751
15 4272
99 4250
10 3285
1 2874
14 2731
8 2536
17 2422
16 2028
2 1775
7 1771
5 1479
11 1362
4 899
3 325
Name: RRAS, dtype: int64
comportamento
[ ]:
df_aux.comportamento.unique()
array([3, 2])
Textuais
UFNASC: UF de nascimento (char = 2). Outras opções: SI - Sem informação; OP - Outro país.
UFRESID: UF de residência (char = 2). Outras opções: OP - Outro país.
CIDADE: Cidade de residência do paciente (char = 200).
[ ]:
df_aux.UFNASC.unique()
array(['SP', 'MG', 'BA', 'PR', 'SI', 'MA', 'SE', 'MT', 'GO', 'PA', 'AM',
'MS', 'RO', 'CE', 'PI', 'AL', 'OP', 'PE', 'ES', 'RJ', 'SC', 'PB',
'RS', 'RN', 'DF', 'AC', 'RR', 'TO', 'AP'], dtype=object)
[ ]:
df_aux.UFRESID.unique()
array(['MG', 'SP', 'MT', 'PA', 'RO', 'ES', 'MS', 'PE', 'PR', 'GO', 'BA',
'SE', 'TO', 'CE', 'RJ', 'PB', 'SC', 'AM', 'MA', 'DF', 'AP', 'AL',
'PI', 'AC', 'RS', 'RR', 'RN', 'OP'], dtype=object)
[ ]:
df_aux.CIDADE.value_counts().head(10)
SAO PAULO 17026
RIBEIRAO PRETO 1452
CAMPINAS 1382
SAO JOSE DO RIO PRETO 1295
PIRACICABA 1002
JUNDIAI 943
SAO BERNARDO DO CAMPO 932
MARILIA 809
GUARULHOS 787
OSASCO 749
Name: CIDADE, dtype: int64
FAIXAETAR: Faixa etária do paciente (char = 5).
00-09
10-19
20-29
30-39
40-49
50-59
60-69
70+
[ ]:
df_aux.FAIXAETAR.unique()
array(['10-19', '00-09', '70+', '60-69', '50-59', '40-49', '30-39',
'20-29'], dtype=object)
DRS: Departamentos Regionais de Saúde (char = 200).
DRS 01 SĂO PAULO
DRS 15 SĂO JOSÉ DO RIO PRETO
DRS 06 BAURU
DRS 07 CAMPINAS
DRS 09 MARÍLIA
DRS 13 RIBEIRĂO PRETO
DRS 10 PIRACICABA
DRS 17 TAUBATÉ
DRS 16 SOROCABA
DRS 05 BARRETOS
DRS 03 ARARAQUARA
DRS 02 ARAÇATUBA
DRS 04 SANTOS
DRS 14 SĂO JOĂO DA BOA VISTA
DRS 08 FRANCA
DRS 11 PRESIDENTE PRUDENTE
DRS 12 REGISTRO
[ ]:
df_aux.DRS.unique()
array([nan, 'DRS 10 PIRACICABA', 'DRS 01 SÃO PAULO', 'DRS 07 CAMPINAS',
'DRS 08 FRANCA', 'DRS 03 ARARAQUARA', 'DRS 06 BAURU',
'DRS 15 SÃO JOSÉ DO RIO PRETO', 'DRS 04 SANTOS',
'DRS 09 MARÍLIA', 'DRS 11 PRESIDENTE PRUDENTE',
'DRS 16 SOROCABA', 'DRS 02 ARAÇATUBA', 'DRS 13 RIBEIRÃO PRETO',
'DRS 05 BARRETOS', 'DRS 17 TAUBATÉ',
'DRS 14 SÃO JOÃO DA BOA VISTA', 'DRS 12 REGISTRO'], dtype=object)
[ ]:
df_aux.DRS.isna().sum()
4250
DESCTOPO: Descrição da Topografia (char = 80).
DESCMORFO: Descrição da morfologia (char = 80).
[ ]:
df_aux.DESCTOPO.value_counts().head(10)
RETO SOE 28308
COLON SIGMOIDE 10445
COLON SOE 8364
COLON ASCENDENTE 5921
JUNCAO RETOSSIGMOIDIANA 4657
COLON DESCENDENTE 3011
COLON TRANSVERSO 2574
CECO 2479
COLON ANGULO HEPATICO DO 716
COLON ANGULO ESPLENICO DO 563
Name: DESCTOPO, dtype: int64
[ ]:
df_aux.DESCMORFO.value_counts().head(10)
ADENOCARCINOMA SOE 38560
ADENOCARCINOMA TUBULAR 19706
ADENOCARCINOMA MUCINOSO 2569
ADENOCARCINOMA EM ADENOMA TUBULOVILOSO 1120
ADENOCARCINOMA VILOSO 642
CARCINOMA SOE 512
CARCINOMA DE CELULAS EM ANEL DE SINETE 499
ADENOCARCINOMA PRODUTOR DE MUCINA 472
ADENOCARCINOMA IN SITU SOE 447
CARCINOMA NEUROENDOCRINO SOE 379
Name: DESCMORFO, dtype: int64
HABILIT
[ ]:
df_aux.HABILIT.value_counts()
CACON 41391
UNACON 26622
Name: HABILIT, dtype: int64
Categorias com letras e números
TOPO: Código da topografia (char = 4). Formato: C999
TOPOGRUP: Grupo da topografia (char = 3). Formato: C99
[ ]:
df_aux.TOPO.nunique()
12
[ ]:
df_aux.TOPOGRUP.unique()
array(['C18', 'C20', 'C19'], dtype=object)
META01: Metástase (char = 3). Formato: C99
META02: Metástase (char = 3). Formato: C99
META03: Metástase (char = 3). Formato: C99
META04: Metástase (char = 3). Formato: C99
[ ]:
print(df_aux.META01.isna().sum())
print(df_aux.META02.isna().sum())
print(df_aux.META03.isna().sum())
print(df_aux.META04.isna().sum())
50921
62582
66500
67634
REC01: Local da recidiva/metástase (char = 3). Formato: C99
REC02: Local da recidiva/metástase (char = 3). Formato: C99
REC03: Local da recidiva/metástase (char = 3). Formato: C99
REC04: Local da recidiva/metástase (char = 3). Formato: C99
[ ]:
print(df_aux.REC01.isna().sum())
print(df_aux.REC02.isna().sum())
print(df_aux.REC03.isna().sum())
print(df_aux.REC04.isna().sum())
59403
65534
67320
68013
EC: Estadio clínico (char = 5). [0,IIIB,IA, …]
ECGRUP: Grupo do estadiamento clínico (char = 3). [0,I,II,III,IV,Y,X]
[ ]:
np.sort(df_aux.EC.unique())
array(['0', 'I', 'II', 'IIA', 'IIB', 'IIC', 'III', 'IIIA', 'IIIB', 'IIIC',
'IV', 'IVA', 'IVB', 'IVC', 'X', 'Y'], dtype=object)
[ ]:
np.sort(df_aux.ECGRUP.unique())
array(['0', 'I', 'II', 'III', 'IV', 'X', 'Y'], dtype=object)
[ ]:
df_aux.ECGRUP.value_counts()
III 19576
II 18092
IV 16842
I 8055
X 3639
Y 973
0 836
Name: ECGRUP, dtype: int64
T: Classificação TNM - T (char = 5).
N: Classificação TNM - N (char = 5).
M: Classificação TNM - M (char = 3).
[ ]:
np.sort(df_aux['T'].unique())
array(['0', '1', '1A', '1B', '2', '3', '4', '4A', '4B', 'IS', 'X', 'Y'],
dtype=object)
[ ]:
np.sort(df_aux['N'].unique())
array(['0', '1', '1A', '1B', '1C', '2', '2A', '2B', 'X', 'Y'],
dtype=object)
[ ]:
np.sort(df_aux['M'].unique())
array(['0', '1', '1A', '1B', 'X', 'Y'], dtype=object)
Primeiro pré-processamento
[ ]:
df = variables_preprocessing(df_aux)
df.head(3)
| ESCOLARI | IDADE | SEXO | IBGE | CATEATEND | DTCONSULT | DIAGPREV | DTDIAG | EC | ECGRUP | ... | CONSDIAG | TRATCONS | DIAGTRAT | ANODIAG | FAIXAETAR | DRS | RRAS | DTRECIDIVA | RECNENHUM | IBGEATEN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 4 | 4 | 19 | 2 | 3538709 | 9 | 2004-06-22 | 2 | 2004-06-22 | IV | IV | ... | 0 | 34.0 | 34.0 | 2004 | 10-19 | 10 | 14 | NaN | 1 | 3538709 |
| 6 | 9 | 19 | 1 | 3537107 | 2 | 2006-12-20 | 2 | 2006-10-17 | IIIA | III | ... | 64 | 6.0 | 70.0 | 2006 | 10-19 | 07 | 15 | NaN | 1 | 3509502 |
| 7 | 4 | 19 | 1 | 3516200 | 9 | 2007-10-05 | 2 | 2007-09-26 | IIB | II | ... | 9 | 6.0 | 15.0 | 2007 | 10-19 | 08 | 13 | NaN | 1 | 3516200 |
3 rows × 33 columns
[ ]:
df.shape
(33565, 33)
[ ]:
df.isna().sum().sort_values(ascending=False).head(8)
DTRECIDIVA 28500
DIAGTRAT 1644
TRATCONS 1644
DTTRAT 1644
DTULTINFO 5
ULTINFO 1
OUTROS 0
NENHUMANT 0
dtype: int64
[ ]:
df.columns
Index(['ESCOLARI', 'IDADE', 'SEXO', 'IBGE', 'CATEATEND', 'DTCONSULT',
'DIAGPREV', 'DTDIAG', 'EC', 'ECGRUP', 'DTTRAT', 'TRATHOSP', 'NENHUM',
'CIRURGIA', 'RADIO', 'QUIMIO', 'HORMONIO', 'TMO', 'IMUNO', 'OUTROS',
'NENHUMANT', 'DTULTINFO', 'ULTINFO', 'CONSDIAG', 'TRATCONS', 'DIAGTRAT',
'ANODIAG', 'FAIXAETAR', 'DRS', 'RRAS', 'DTRECIDIVA', 'RECNENHUM',
'IBGEATEN'],
dtype='object')
[ ]:
save_csv(df, '/content/drive/MyDrive/Trabalho/Cancer/Datasets/colorretal_pp.csv')
CSV file saved successfully!
Criação de novas colunas
Nesta seção, novas colunas serão criadas baseadas na diferença em dias das datas e na coluna de última informação.
[ ]:
df = read_csv('/content/drive/MyDrive/Trabalho/Cancer/Datasets/colorretal_pp.csv')
df.head(2)
(33565, 33)
| ESCOLARI | IDADE | SEXO | IBGE | CATEATEND | DTCONSULT | DIAGPREV | DTDIAG | EC | ECGRUP | ... | CONSDIAG | TRATCONS | DIAGTRAT | ANODIAG | FAIXAETAR | DRS | RRAS | DTRECIDIVA | RECNENHUM | IBGEATEN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 19 | 2 | 3538709 | 9 | 2004-06-22 | 2 | 2004-06-22 | IV | IV | ... | 0 | 34.0 | 34.0 | 2004 | 10-19 | 10 | 14 | NaN | 1 | 3538709 |
| 1 | 9 | 19 | 1 | 3537107 | 2 | 2006-12-20 | 2 | 2006-10-17 | IIIA | III | ... | 64 | 6.0 | 70.0 | 2006 | 10-19 | 7 | 15 | NaN | 1 | 3509502 |
2 rows × 33 columns
[ ]:
# NULL! to NaN
df.loc[df.DTRECIDIVA == '#NULL!', 'DTRECIDIVA'] = np.nan
df.loc[df.DTTRAT == '#NULL!', 'DTTRAT'] = np.nan
df.loc[df.DTULTINFO == '#NULL!', 'DTULTINFO'] = np.nan
[ ]:
# Dates - DTCONSULT, DTDIAG, DTTRAT, DTULTINFO, DTRECIDIVA
lista_datas = ['DTCONSULT', 'DTDIAG', 'DTTRAT', 'DTULTINFO', 'DTRECIDIVA']
df[lista_datas].isna().sum()
DTCONSULT 0
DTDIAG 0
DTTRAT 1644
DTULTINFO 5
DTRECIDIVA 28500
dtype: int64
[ ]:
df[lista_datas].head(10)
| DTCONSULT | DTDIAG | DTTRAT | DTULTINFO | DTRECIDIVA | |
|---|---|---|---|---|---|
| 0 | 2004-06-22 | 2004-06-22 | 2004-07-26 00:00:00 | 2018-02-14 00:00:00 | NaN |
| 1 | 2006-12-20 | 2006-10-17 | 2006-12-26 00:00:00 | 2014-04-22 00:00:00 | NaN |
| 2 | 2007-10-05 | 2007-09-26 | 2007-10-11 00:00:00 | 2020-09-11 00:00:00 | NaN |
| 3 | 2015-06-09 | 2015-06-10 | NaN | 2015-07-13 00:00:00 | NaN |
| 4 | 2015-02-26 | 2015-03-20 | 2015-04-10 00:00:00 | 2015-08-02 00:00:00 | NaN |
| 5 | 2017-06-22 | 2017-06-01 | 2017-08-01 00:00:00 | 2019-02-14 00:00:00 | NaN |
| 6 | 2021-07-12 | 2021-06-09 | 2021-07-12 00:00:00 | 2021-07-12 00:00:00 | NaN |
| 7 | 2013-08-20 | 2013-08-20 | 2013-08-20 00:00:00 | 2021-02-15 00:00:00 | 2018-04-18 00:00:00 |
| 8 | 2010-12-28 | 2010-12-31 | 2011-01-11 00:00:00 | 2012-05-05 00:00:00 | 2012-01-11 00:00:00 |
| 9 | 2010-12-12 | 2010-12-12 | 2011-02-17 00:00:00 | 2011-02-19 00:00:00 | NaN |
Colunas das diferença de datas
Serão calculadas as diferenças entre as datas de consulta, diagnóstico e tratamento e, a seguir, a diferença entre a data da última informação e as três primeiras.
Este processo será realizado pela função get_dates_diff, que descarta as linhas vazias das colunas DTTRAT e DTULTINFO, converte as colunas de data para o formato datetime e então calcula a diferença entre as datas em dias.
A ideia está apresentada abaixo.
Veja a função completa na seção de funções.
Colunas de datas
Consulta - \(t_1\)
Diagnóstico - \(t_2\)
Tratamento - \(t_3\)
Recidiva - \(t_4\)
Última informação - \(t_5\)
Diferença, em dias, entre as datas:
Última informação:
[ ]:
dates = ['CONSDIAG', 'DIAGTRAT', 'TRATCONS', 'ULTICONS', 'ULTIDIAG', 'ULTITRAT']
[ ]:
df = get_dates_diff(df, lista_datas)
print(df.shape)
df[dates].head(3)
(31916, 31)
| CONSDIAG | DIAGTRAT | TRATCONS | ULTICONS | ULTIDIAG | ULTITRAT | |
|---|---|---|---|---|---|---|
| 0 | 0 | 34 | 34 | 4985 | 4985 | 4951 |
| 1 | -64 | 70 | 6 | 2680 | 2744 | 2674 |
| 2 | -9 | 15 | 6 | 4725 | 4734 | 4719 |
[ ]:
df.head(3)
| ESCOLARI | IDADE | SEXO | IBGE | CATEATEND | DIAGPREV | EC | ECGRUP | TRATHOSP | NENHUM | ... | DIAGTRAT | ANODIAG | FAIXAETAR | DRS | RRAS | RECNENHUM | IBGEATEN | ULTICONS | ULTIDIAG | ULTITRAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 19 | 2 | 3538709 | 9 | 2 | IV | IV | I | 0 | ... | 34 | 2004 | 10-19 | 10 | 14 | 1 | 3538709 | 4985 | 4985 | 4951 |
| 1 | 9 | 19 | 1 | 3537107 | 2 | 2 | IIIA | III | I | 0 | ... | 70 | 2006 | 10-19 | 7 | 15 | 1 | 3509502 | 2680 | 2744 | 2674 |
| 2 | 4 | 19 | 1 | 3516200 | 9 | 2 | IIB | II | F | 0 | ... | 15 | 2007 | 10-19 | 8 | 13 | 1 | 3516200 | 4725 | 4734 | 4719 |
3 rows × 31 columns
Criação do label de óbito
Nesta seção, rótulos serão criados com base nas informações mais recentes, uma coluna apenas se a pessoa morreu ou não (obito_geral) e outra para morte por câncer (obito_cancer).
Outras três colunas terão a informação de quantos anos após o diagnóstico a pessoa viveu (vivo_ano1, vivo_ano3, vivo_ano5).
Este processo vai ser feito pela função
get_labels, disponível na seção das funções.
Labels de óbito
Óbito por qualquer razão - obito_geral;
Óbito por câncer - obito_cancer;
Paciente vivo após um ano - vivo_ano1;
Paciente vivo após três anos - vivo_ano3;
Paciente vivo após cinco anos - vivo_ano5.
Última informação
1 - Vivo com câncer
2 - Vivo, sem outras informações
3 - Óbito por câncer
4 - Óbitos por outras causas
[ ]:
df.head(2)
| ESCOLARI | IDADE | SEXO | IBGE | CATEATEND | DIAGPREV | EC | ECGRUP | TRATHOSP | NENHUM | ... | DIAGTRAT | ANODIAG | FAIXAETAR | DRS | RRAS | RECNENHUM | IBGEATEN | ULTICONS | ULTIDIAG | ULTITRAT | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4 | 19 | 2 | 3538709 | 9 | 2 | IV | IV | I | 0 | ... | 34 | 2004 | 10-19 | 10 | 14 | 1 | 3538709 | 4985 | 4985 | 4951 |
| 1 | 9 | 19 | 1 | 3537107 | 2 | 2 | IIIA | III | I | 0 | ... | 70 | 2006 | 10-19 | 7 | 15 | 1 | 3509502 | 2680 | 2744 | 2674 |
2 rows × 31 columns
[ ]:
df.ULTINFO.value_counts()
3.0 13136
2.0 10430
1.0 4589
4.0 3761
Name: ULTINFO, dtype: int64
[ ]:
df = get_labels(df)
df.shape
(31916, 36)
[ ]:
columns = ['ULTINFO', 'obito_geral', 'obito_cancer', 'vivo_ano1', 'vivo_ano3', 'vivo_ano5']
df[columns].head(2)
| ULTINFO | obito_geral | obito_cancer | vivo_ano1 | vivo_ano3 | vivo_ano5 | |
|---|---|---|---|---|---|---|
| 0 | 2.0 | 0 | 0 | 1 | 1 | 1 |
| 1 | 3.0 | 1 | 1 | 1 | 1 | 1 |
[ ]:
df[columns][df.obito_geral == 0].head(10)
| ULTINFO | obito_geral | obito_cancer | vivo_ano1 | vivo_ano3 | vivo_ano5 | |
|---|---|---|---|---|---|---|
| 0 | 2.0 | 0 | 0 | 1 | 1 | 1 |
| 2 | 2.0 | 0 | 0 | 1 | 1 | 1 |
| 5 | 2.0 | 0 | 0 | 1 | 0 | 0 |
| 6 | 1.0 | 0 | 0 | 0 | 0 | 0 |
| 7 | 1.0 | 0 | 0 | 1 | 1 | 1 |
| 21 | 1.0 | 0 | 0 | 0 | 0 | 0 |
| 22 | 1.0 | 0 | 0 | 0 | 0 | 0 |
| 29 | 2.0 | 0 | 0 | 1 | 1 | 1 |
| 31 | 2.0 | 0 | 0 | 1 | 1 | 1 |
| 33 | 2.0 | 0 | 0 | 1 | 1 | 1 |
Inputer escolaridade
Os valores 9 da variável ESCOLARI serão inseridos usando as colunas IDADE, ECGRUP e SEXO.
[ ]:
cols = ['ESCOLARI', 'IDADE', 'ECGRUP', 'SEXO']
df_esc = df[cols].copy()
df_esc.head(3)
| ESCOLARI | IDADE | ECGRUP | SEXO | |
|---|---|---|---|---|
| 0 | 4 | 19 | IV | 2 |
| 1 | 9 | 19 | III | 1 |
| 2 | 4 | 19 | II | 1 |
[ ]:
df_esc.loc[df_esc.ESCOLARI == 9, 'ESCOLARI'] = np.nan
df_esc.loc[df_esc.ECGRUP == 'I', 'ECGRUP'] = 1
df_esc.loc[df_esc.ECGRUP == 'II', 'ECGRUP'] = 2
df_esc.loc[df_esc.ECGRUP == 'III', 'ECGRUP'] = 3
df_esc.loc[df_esc.ECGRUP == 'IV', 'ECGRUP'] = 4
df_esc.ESCOLARI.value_counts(dropna=False)
NaN 9759
2.0 8580
3.0 6041
4.0 4155
5.0 2116
1.0 1265
Name: ESCOLARI, dtype: int64
[ ]:
from sklearn.impute import KNNImputer
X = df_esc.values
imputer = KNNImputer(n_neighbors=5, weights='distance')
df_esc.ESCOLARI = imputer.fit_transform(X)
df_esc.head(3)
| ESCOLARI | IDADE | ECGRUP | SEXO | |
|---|---|---|---|---|
| 0 | 4.000000 | 19 | 4 | 2 |
| 1 | 3.546918 | 19 | 3 | 1 |
| 2 | 4.000000 | 19 | 2 | 1 |
[ ]:
df['ESCOLARI_2'] = df_esc.ESCOLARI.round()
df.ESCOLARI_2.value_counts(dropna=False)
3.0 11666
2.0 11291
4.0 5544
5.0 2122
1.0 1293
Name: ESCOLARI_2, dtype: int64
[ ]:
df.ESCOLARI.value_counts()
9 9759
2 8580
3 6041
4 4155
5 2116
1 1265
Name: ESCOLARI, dtype: int64
[ ]:
save_csv(df, '/content/drive/MyDrive/Trabalho/Cancer/Datasets/colorretal_labels.csv')
CSV file saved successfully!